 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Entrer dans le domaine de l’analyse des systèmes apporte une vague de nouveaux concepts, de terminologies et de diagrammes. Parmi ceux-ci, le diagramme de flux de données (DFD) constitue une pierre angulaire pour visualiser le déplacement de l’information à travers un système. Il offre une image claire des processus, du stockage des données et des interactions externes, sans s’attarder aux détails techniques d’implémentation. Toutefois, pour ceux qui débutent dans ce rôle, comprendre les subtilités peut s’avérer difficile. Ce guide aborde les dix questions les plus fréquentes posées par les analystes au début de leur parcours avec les DFD. Nous explorerons les définitions, les distinctions et les bonnes pratiques qui garantissent que vos diagrammes communiquent efficacement avec les parties prenantes et les développeurs.
Un diagramme de flux de données est une représentation graphique du déplacement des données à travers un système d’information. Contrairement à un organigramme, qui illustre la séquence des opérations ou le flux de contrôle, un DFD se concentre sur le mouvement des données. Il répond à la question : « D’où proviennent les données, où vont-elles et comment évoluent-elles en chemin ? » Cette abstraction permet aux parties prenantes de comprendre les exigences logiques d’un système sans avoir besoin de connaître le langage de programmation ou le schéma de base de données utilisé.
Les caractéristiques principales incluent :
Comprendre cette distinction est essentiel. Lorsqu’un analyste crée un DFD, il établit une carte de la logique métier. Cette carte agit comme un pont entre les exigences métiers et les spécifications techniques, garantissant que tous s’accordent sur le parcours des données avant qu’une seule ligne de code ne soit écrite.
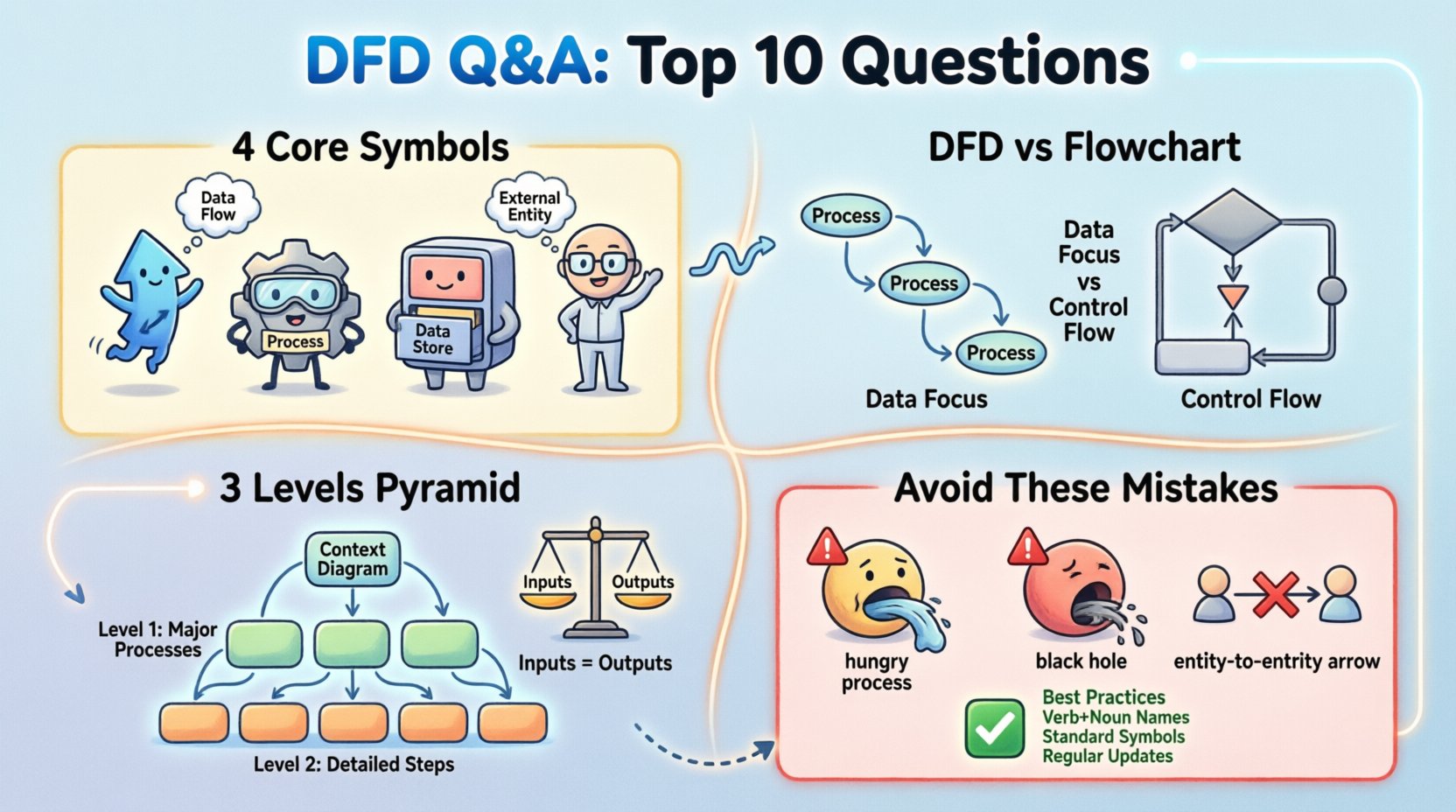
C’est un point de confusion fréquent. Bien que les deux utilisent des formes et des flèches, leurs objectifs sont fondamentalement différents. Un organigramme illustre le flux de contrôle d’un programme ou d’une procédure. Il montre les points de décision (oui/non), les boucles et la séquence exacte des étapes. Il est souvent trop détaillé pour une analyse systématique de haut niveau.
Inversement, un DFD abstrait la logique de contrôle. Il ne montre ni les boucles ni les branches de décision. Il illustre plutôt la transformation des données. Si vous concevez une base de données, un organigramme pourrait montrer la logique des requêtes. Un DFD montrerait les données passant d’un formulaire utilisateur vers la table de la base de données.
Les différences clés à retenir :
Les DFD standards reposent sur quatre symboles spécifiques pour représenter les composants du système. Leur utilisation cohérente garantit que quiconque lit le diagramme comprend immédiatement la notation.
| Symbole | Nom | Fonction | Représentation visuelle |
|---|---|---|---|
| Flèche | Flux de données | Montre le déplacement des données entre les composants | Ligne étiquetée |
| Cercle ou rectangle arrondi | Processus | Transforme les données d’entrée en données de sortie | Cercle / Boîte |
| Rectangle ouvert | Stockage de données | Stocke les données pour une utilisation ultérieure | Deux lignes parallèles / Boîte |
| Rectangle | Entité externe | Source ou destination des données en dehors du système | Boîte |
Chaque symbole joue un rôle distinct. Le processus modifie les données. Le stockage de données les conserve. L’entité externe les fournit ou les consomme. Le flux de données les relie. Les confondre peut entraîner des malentendus importants pendant la phase de développement.
Les systèmes complexes nécessitent différents niveaux de détail pour rester compréhensibles. Nous divisons généralement les diagrammes en flux de données en trois niveaux hiérarchiques. Ce processus est connu sous le nom de « décomposition » ou « explosion » du diagramme.
Chaque niveau doit maintenir une cohérence avec celui qui le précède. Vous ne pouvez pas introduire de nouveaux flux de données au niveau inférieur qui n’existaient pas au niveau supérieur, sauf s’ils sont correctement équilibrés.
L’équilibrage est une règle essentielle qui garantit l’intégrité de votre diagramme à travers les niveaux. Elle stipule que les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties des processus enfants situés en dessous. Si un processus de niveau 1 a une entrée « ID utilisateur », le diagramme de niveau 2 qui décompose ce processus doit également montrer l’entrée de « ID utilisateur » dans les sous-processus.
Violer l’équilibrage crée de la confusion. Cela suggère que les données sont créées ou détruites magiquement, ce qui est impossible dans un système logique. Lors de la revue d’un diagramme, vérifiez toujours les bords. Si une ligne entre dans une boîte au niveau 1, cette ligne doit apparaître dans le diagramme correspondant au niveau 2.
Pourquoi cela importe-t-il :
Les noms ne sont pas seulement des étiquettes ; ils sont une documentation. Un nom de processus doit être un verbe suivi d’un nom. Par exemple, « Calculer la taxe » est préférable à « Calcul de la taxe ». Le verbe indique une action ou une transformation, tandis que le nom indique le sujet traité.
Les erreurs courantes de nommage incluent :
La cohérence dans le nommage aide les analystes à parcourir rapidement le diagramme et à comprendre la fonction de chaque composant sans avoir besoin de légende.
Dans un DFD, un magasin de données représente un endroit où les données sont stockées. Il s’agit d’un concept logique. Dans le système physique, cela pourrait être une table SQL, un fichier plat, une feuille de calcul ou un conteneur cloud. Le DFD ne tient pas compte de la technologie d’implémentation.
Toutefois, une erreur courante consiste à traiter le magasin de données comme un tampon temporaire. Un magasin de données doit être persistant. Si le système s’arrête, les données restent. Cela le distingue des flux de données transitoires.
Lors de la conception du système physique ultérieurement, l’analyste ou l’architecte doit mapper chaque magasin de données à une solution de stockage physique. Si un magasin de données est étiqueté « Dossiers clients », l’équipe de base de données sait qu’il faut créer une table avec cette structure. Si le DFD implique qu’aucun stockage n’est nécessaire pour un flux de données spécifique, aucune table de base de données ne doit être créée pour celui-ci.
Les entités externes sont des personnes, des organisations ou d’autres systèmes qui interagissent avec le système modélisé, mais qui existent en dehors de sa frontière. Elles sont la source ou la destination des données.
Les exemples incluent :
Il est crucial de faire la distinction entre une entité à l’intérieur du système et une entité à l’extérieur. Si un composant fait partie de la logique interne du système, il doit être un Processus ou un Magasin de Données. Si elle est à l’extérieur de la frontière, c’est une Entité. Confondre ces deux éléments peut entraîner une expansion du périmètre, où les développeurs sont amenés à construire des composants appartenant à des systèmes tiers.
Même les analystes expérimentés commettent des erreurs. Identifier ces pièges courants dès le début peut éviter un travail de reprise important plus tard. Ci-dessous figurent les problèmes les plus fréquents rencontrés dans les premiers brouillons.
Passer en revue vos schémas à l’aide de cette liste de contrôle peut améliorer significativement leur qualité avant la présentation aux parties prenantes.
Un schéma n’est pas un artefact statique ; c’est un document vivant. Au fur et à mesure que les exigences métier évoluent, le système doit évoluer lui aussi. Si le processus « Calculer la remise » change en « Appliquer une remise par tranches », le schéma de flux de données doit être mis à jour. Ne pas mettre à jour le schéma entraîne un décalage entre la documentation et le logiciel réel.
Les meilleures pratiques de maintenance incluent :
Traiter le schéma de flux de données comme un document de référence qui doit être maintenu à jour garantit que les développeurs et analystes futurs peuvent comprendre le système sans se fier uniquement à la mémoire ou à des notes obsolètes.
Pour garantir que vos schémas de flux de données remplissent efficacement leur rôle, respectez ces principes fondamentaux. La clarté est l’objectif principal. Si une partie prenante ne comprend pas le flux de données après un simple regard, le schéma a échoué à son objectif. Utilisez les symboles standards de manière cohérente. Gardez les niveaux distincts. Nommez clairement vos processus. Équilibrez vos entrées et sorties. Et rappelez-vous toujours que le schéma est un outil de communication, et non seulement une exigence technique.
En maîtrisant ces concepts fondamentaux, vous construisez une base solide pour l’analyse de systèmes complexes. Vous fournissez une feuille de route claire aux équipes de développement et une vision claire des exigences aux dirigeants. Cette compréhension partagée est la clé de la mise en œuvre réussie du système.
Souvenez-vous, la valeur d’un schéma de flux de données réside dans sa capacité à simplifier la complexité. Il vous permet de voir à la fois la forêt et les arbres. Utilisez-le pour guider votre analyse, valider vos exigences et communiquer votre vision. Avec de la pratique, la création de ces schémas deviendra une étape naturelle de votre workflow, vous aidant à naviguer avec confiance dans les subtilités de la conception de système.