 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











L’intégration système est le pilier de l’infrastructure numérique moderne. Elle relie des applications, des bases de données et des services disparates pour qu’ils fonctionnent comme une unité cohérente. Cependant, la complexité des données qui circulent entre ces systèmes peut devenir rapidement opaque. C’est là qu’intervient le diagramme de flux de données (DFD), qui devient essentiel. Un DFD fournit une représentation visuelle du parcours des données à travers un système, en mettant en évidence les entrées, les traitements, le stockage et les sorties. Lorsqu’il est appliqué à l’intégration système, il sert de plan directeur pour comprendre l’origine des données et leurs dépendances.
Sans une carte claire, les projets d’intégration risquent des incohérences de données, des vulnérabilités de sécurité et des goulets d’étranglement. En visualisant les flux de données à travers plusieurs composants, les architectes et ingénieurs peuvent repérer les lacunes avant qu’elles ne deviennent des défaillances critiques. Ce guide explore la méthodologie de l’utilisation des DFD spécifiquement dans le contexte de l’intégration de systèmes complexes.
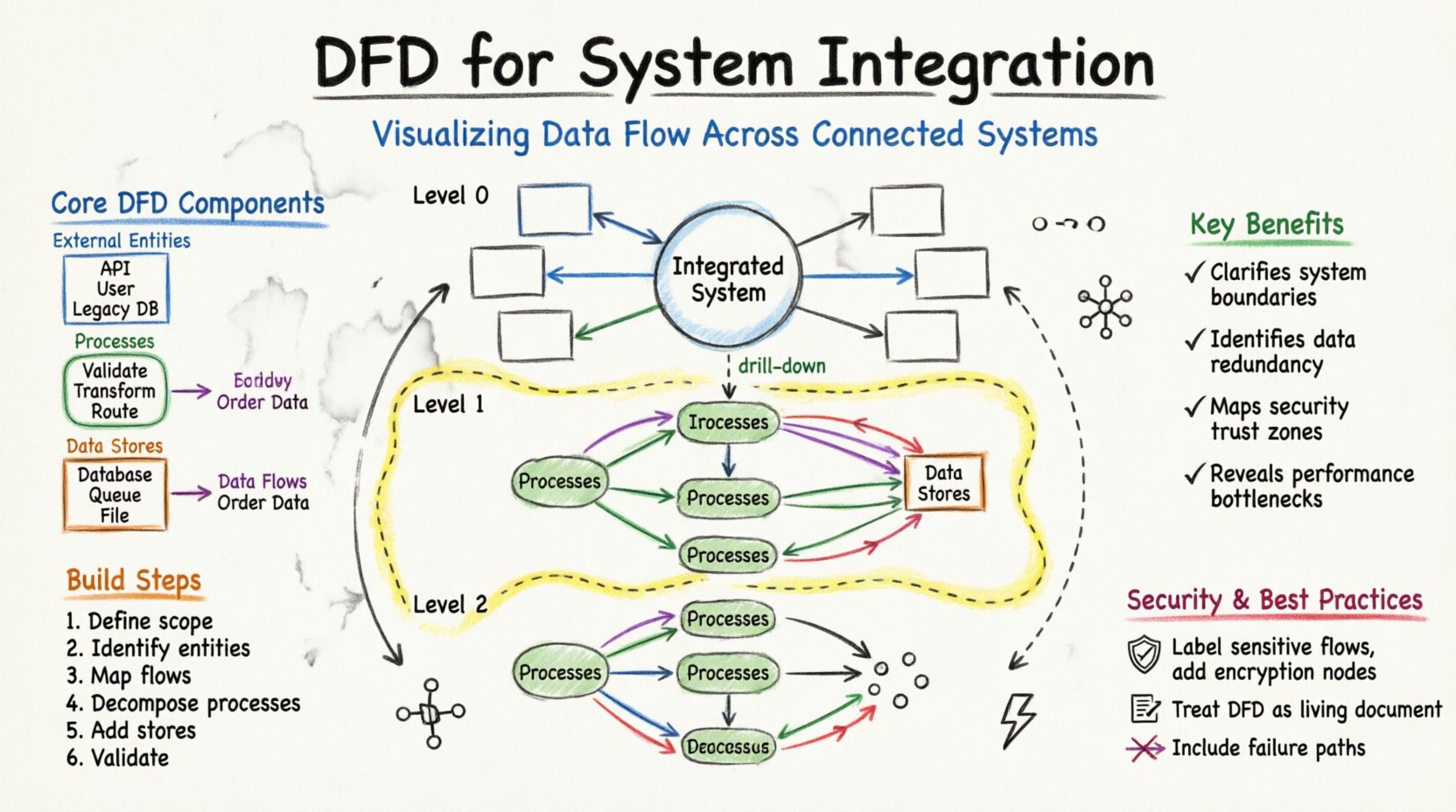
Avant de s’immerger dans les spécificités de l’intégration, il est nécessaire de comprendre les éléments fondamentaux d’un DFD. Ces éléments restent constants, quelle que soit la complexité du système.
Il est important de distinguer les DFD des diagrammes de flux. Les diagrammes de flux se concentrent sur le flux de contrôle et la logique décisionnelle (chemins if/else). Les DFD se concentrent strictement sur le mouvement des données. Dans l’intégration système, l’intégrité des données est souvent plus critique que le chemin décisionnel précis suivi. Par conséquent, un DFD est l’outil privilégié pour cartographier les pipelines de transformation des données.
Lorsque plusieurs systèmes doivent communiquer, l’architecture ressemble souvent à un maillage. Sans visualisation centrale, les connexions peuvent devenir un réseau enchevêtré. Un DFD aide à clarifier cette complexité en stratifiant les informations.
Pour gérer la complexité, les DFD sont généralement créés à différents niveaux d’abstraction. Cette hiérarchie permet aux parties prenantes de visualiser le système à partir d’un aperçu global jusqu’aux détails techniques spécifiques.
Le diagramme de contexte est le niveau d’abstraction le plus élevé. Il considère l’ensemble du système intégré comme un seul processus. Il montre l’interaction du système avec les entités externes.
Ce diagramme divise le processus principal en sous-processus majeurs. Il constitue la carte principale pour les architectes d’intégration.
Les diagrammes de niveau 2 approfondissent des sous-processus spécifiques du niveau 1. Ils sont utilisés par les développeurs et ingénieurs mettant en œuvre une logique spécifique.
La création d’un DFD robuste exige une approche structurée. Ce n’est pas simplement un exercice de dessin, mais une activité de modélisation qui nécessite une compréhension de la logique métier.
Commencez par énumérer tous les systèmes participant à l’intégration. Distinctez les systèmes qui génèrent des données de ceux qui les consomment. Définissez la frontière organisationnelle. Quels flux de données sont internes, et lesquels traversent le domaine public ?
Listez chaque source et chaque destination. Cela inclut :
Tracez des flèches reliant les entités au système central. Étiquetez ces flux avec le type de données échangées (par exemple, « Détails de la commande », « Statut des stocks »). Ne vous inquiétez pas encore de la logique interne. Concentrez-vous sur le déplacement.
Divisez le système central en processus logiques. Par exemple, au lieu d’un seul processus appelé « Gérer la commande », divisez-le en « Valider la commande », « Vérifier les stocks » et « Traiter le paiement ». Cette décomposition révèle où les données sont transformées.
Identifiez où les données doivent être stockées. Dans une intégration, cela peut être une zone de staging temporaire ou un entrepôt permanent. Assurez-vous que chaque magasin de données est connecté à un processus qui l’écrit et à un processus qui le lit.
Vérifiez les erreurs courantes. Assurez-vous qu’aucun flux de données ne commence ni ne se termine dans le vide. Chaque flèche doit avoir un point de départ et un point d’arrivée. Vérifiez que les magasins de données ne sont pas contournés lorsque les données doivent être conservées.
La construction de DFD pour l’intégration n’est pas sans obstacles. L’incohérence des données et les dépendances cachées sont des pièges fréquents. Le tableau ci-dessous décrit les problèmes courants et les approches recommandées pour les résoudre.
| Défi | Description | Solution |
|---|---|---|
| Redondance des données | Plusieurs systèmes stockent indépendamment les mêmes informations clients. | Consolidez les magasins de données dans le DFD vers une seule source de vérité, lorsque cela est possible. |
| Dépendances cachées | Les flux de données dépendent de tâches en arrière-plan invisibles sur le diagramme. | Incluez les processus asynchrones et les tâches en arrière-plan comme des processus explicites dans le DFD. |
| Failles de sécurité | Des flux de données non chiffrés circulent sur des réseaux publics. | Étiquetez les flux sécurisés et appliquez des processus de chiffrement aux frontières du réseau. |
| Interfaces de systèmes hérités | Les anciens systèmes ne disposent pas d’API standard. | Modélisez l’enveloppe ou le middleware requis pour traduire les formats de données. |
| Pic de volume | Le flux de données augmente de manière inattendue pendant les périodes de pointe. | Ajoutez des magasins de données tampon pour absorber les pics de trafic avant le traitement. |
Pour garantir que le DFD reste utile au fil du temps, respectez ces principes de conception. Un schéma trop complexe devient illisible ; un schéma trop simple devient inexact.
L’intégration système implique rarement des données qui se déplacent exactement telles quelles. Les formats changent, des champs sont ajoutés, et des valeurs sont calculées. Le DFD doit refléter ces transformations.
Lorsqu’une donnée entre dans un système, elle doit souvent être standardisée. Par exemple, un format de date peut être « JJ/MM/AAAA » dans un système et « AAAA-MM-JJ » dans un autre. Le DFD doit montrer un nœud de processus spécifiquement dédié à la « standardisation des formats ».
Parfois, les données sont combinées avec d’autres sources afin d’ajouter de la valeur. Par exemple, une commande peut être enrichie avec les taux de change actuels. Cela nécessite un processus qui extrait des données d’une source secondaire (comme une base de données de devises) et les fusionne avec le flux principal.
Les exigences de sécurité imposent souvent que les données sensibles soient masquées. Si un processus envoie des données à un système de journalisation, le DFD doit montrer une étape de transformation qui masque les numéros de carte bancaire ou les numéros de sécurité sociale avant que les données quittent la zone sécurisée.
Les différents modèles architecturaux utilisent les flux de données de manière différente. Comprendre ces modèles aide à dessiner le DFD correct.
Un DFD n’est pas un artefact ponctuel. Les systèmes évoluent, de nouvelles APIs sont introduites, et les anciennes sont dépréciées. Un diagramme obsolète peut entraîner des bogues et des failles de sécurité. La maintenance est une phase cruciale du cycle de vie du DFD.
Les mises à jour du DFD doivent être déclenchées par :
Maintenez le diagramme lié à la base de code ou aux fichiers de configuration. Lorsqu’un développeur modifie un script de mappage des données, il doit mettre à jour le DFD simultanément. Cela garantit que la documentation reste la source de vérité.
La sécurité n’est pas un ajout ; elle est un aspect fondamental du flux de données. En visualisant les données, vous devez tenir compte de l’emplacement des frontières de confiance.
Pour illustrer l’application pratique, envisagez un scénario où une entreprise vend des produits via un site web, une application mobile et un magasin physique.
Les entités incluent le Site web, l’Application mobile, le système de caisse (POS) et le Client.
Les processus clés incluent « Ingérence de commande », « Déduction de stock » et « Traitement du paiement ».
Lorsqu’un client achète un article :
Cette visualisation montre clairement que si le magasin de stock est hors service, l’ingestion de commande pourrait réussir, mais la livraison échouerait. Ce dépendance est visible uniquement à travers le diagramme.
Les diagrammes de flux de données offrent une méthode structurée pour comprendre le déplacement de l’information au sein des intégrations de systèmes complexes. Ils transforment le code abstrait et les appels d’API en un langage visuel que les parties prenantes peuvent comprendre. En suivant les étapes décrites ici, les équipes peuvent créer des cartes précises de leur architecture des données.
Les DFD efficaces conduisent à une meilleure conception du système, à moins d’erreurs d’intégration et à des frontières de sécurité plus claires. Ils servent de document vivant qui guide le développement et la maintenance. Dans un environnement où les données sont l’actif le plus précieux, visualiser leur parcours n’est pas facultatif — c’est une nécessité pour l’excellence opérationnelle.