 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











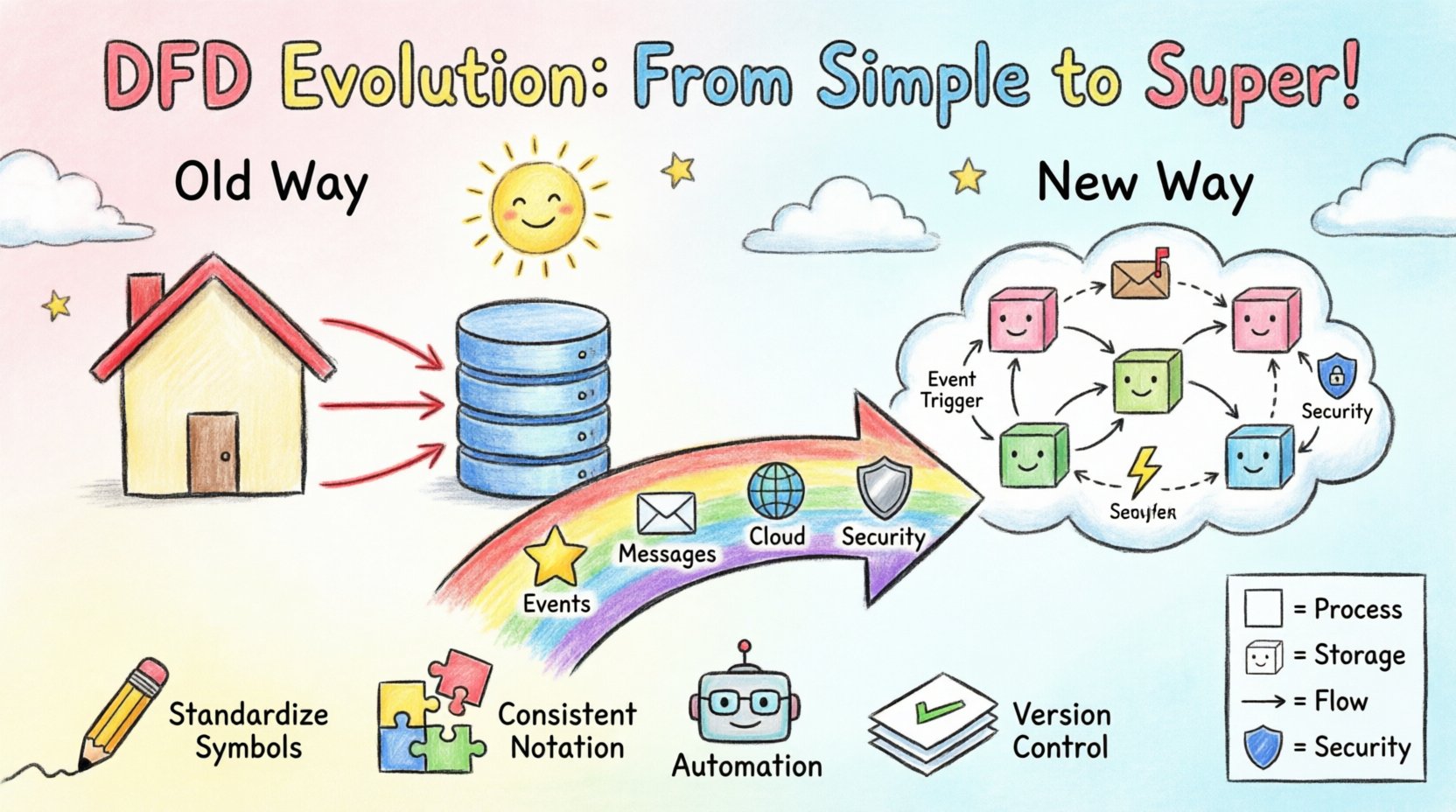
L’analyse des systèmes s’est longtemps appuyée sur des représentations visuelles pour communiquer des logiques complexes. Le diagramme de flux de données (DFD) reste une pierre angulaire de cette pratique. Toutefois, le paysage de l’architecture logicielle a évolué de manière radicale. Nous sommes passés des applications monolithiques aux microservices distribués, des bases de données locales aux stockages natifs du cloud, et des requêtes synchrones aux flux d’événements asynchrones. Le DFD traditionnel, conçu pour des processus simples et linéaires, fait face à de nouveaux défis dans ces environnements. Ce guide explore comment la méthodologie évolue pour rester pertinente, assurant une modélisation précise sans devenir obsolète. 🛠️
Avant d’examiner l’évolution, il est nécessaire de fixer la base. Un DFD standard visualise le flux d’information à travers un système. Il se concentre sur ce que le système fait, et non pas comment il le fait. Cette distinction sépare la modélisation des processus de la conception structurale. Les composants fondamentaux restent constants à travers les générations :
Dans le contexte traditionnel, ces diagrammes étaient hiérarchiques. Un diagramme de contexte offrait une vue d’ensemble (niveau 0), qui était ensuite décomposée en diagrammes détaillés de niveau 1 et niveau 2. Cela fonctionnait bien lorsque le système avait un début et une fin clairs, et que les données se déplaçaient de manière prévisible de l’entrée à la sortie. Toutefois, les systèmes modernes manquent souvent d’un point d’entrée unique ou d’une sortie définitive. Les données entrent et sortent continuellement, souvent en temps réel. 🔄
Le passage des monolithes aux systèmes distribués introduit des frictions dans la modélisation statique. Dans une application monolithique, une transaction de base de données pourrait déclencher une série d’appels de fonctions qui s’achèvent instantanément. Un DFD pourrait tracer une ligne droite depuis la base de données jusqu’au processus puis à la sortie. Dans un environnement de microservices, la situation est bien plus complexe.
Les systèmes modernes comptent fréquemment sur des brokers de messages et des files d’attente. Une requête est reçue, stockée dans une file d’attente, puis traitée ultérieurement par un worker. Les DFD traditionnels peinent à représenter le temps. Ils impliquent un flux immédiat. Une flèche statique ne transmet pas facilement l’idée que les données pourraient rester dans un tampon pendant des heures avant que le prochain processus ne s’active. Cela entraîne une ambiguïté dans l’analyse du comportement du système.
Les architectures cloud utilisent souvent des conteneurs sans état qui s’activent et se désactivent. Un DFD suppose généralement un processus permanent. Lorsqu’un processus est éphémère, le diagramme doit préciser où l’état est conservé (la base de données) par rapport à l’emplacement de la logique (le calcul). Si le diagramme ne distingue pas clairement les deux, les développeurs peuvent supposer à tort que l’état est maintenu à l’intérieur du processus lui-même, ce qui entraîne des bogues.
Les anciens modèles traitaient souvent les bases de données comme des boîtes génériques. La conformité moderne exige de comprendre où les données sont physiquement situées et comment elles sont chiffrées. Un DFD doit désormais indiquer la souveraineté des données et les niveaux de sécurité. Si un flux de données traverse une zone de sécurité, le diagramme doit refléter cette frontière, et non seulement la connexion logique.
Pour combler ces lacunes, les praticiens modifient la notation standard afin d’adapter les architectures orientées événements (EDA). Le concept fondamental reste le flux de données, mais les déclencheurs changent.
Cette adaptation exige un changement de perspective. Le diagramme n’est plus simplement une carte du système ; c’est une carte des incidents qui pilotent le système. Il aide les parties prenantes à comprendre le cycle de vie d’un ensemble de données, de sa création à sa consommation finale, y compris les pauses intermédiaires. 🕒
À mesure que les applications migrent vers le cloud, le DFD doit s’aligner sur les contrats API et les frontières des services. Le diagramme sert de pont entre les exigences métiers et la mise en œuvre technique.
La plupart des systèmes modernes exposent une passerelle API. Dans un DFD, cela remplace l’entité externe générique. La passerelle devient un processus spécifique chargé du routage, de l’authentification et du contrôle de débit. Le diagramme doit montrer la transformation de la requête entrante en une commande interne. Cela clarifie la séparation des préoccupations.
Dans les bases de données distribuées, les données sont souvent fragmentées. Un symbole traditionnel de magasin de données est insuffisant. Le diagramme doit indiquer qu’un processus peut interroger plusieurs fragments pour assembler une réponse. Cela visualise la complexité des opérations de lecture par rapport aux opérations d’écriture. Par exemple, une écriture peut aller vers une seule partition, tandis qu’une lecture agrège des données provenant de trois.
Les services ne connaissent souvent pas à l’avance l’adresse réseau des autres services. Ils les découvrent à l’exécution. Un DFD peut représenter cela en utilisant un nœud « Registre de services ». Les processus se connectent au registre pour trouver l’adresse actuelle d’un service dépendant. Cela ajoute une couche de visibilité de l’infrastructure au flux logique.
Comprendre les différences aide les équipes à choisir le bon niveau d’abstraction. Le tableau suivant décrit les principales différences dans la manière dont les DFD sont construits et interprétés aujourd’hui par rapport au passé.
| Fonctionnalité | DFD traditionnel | DFD moderne |
|---|---|---|
| Direction du flux | Synchrones, immédiats | Asynchrones, retardés ou par lots |
| Nature du processus | Monolithique, longue durée | Microservice, éphémère, sans état |
| Stockage | Base de données centralisée | Fragmentée, distribuée ou stockage d’objets |
| Déclencheurs | Arrivée des données d’entrée | Événements, messages ou tâches planifiées |
| Frontières | Périmètre du système | Zones de sécurité et passerelles API |
| Concurrence | Souvent ignoré | Modélisé explicitement (files d’attente, verrous) |
À mesure que les diagrammes deviennent plus complexes, la lisibilité devient un risque. Les pratiques suivantes garantissent que le DFD reste un outil utile plutôt qu’un artefact confus.
La sécurité n’est plus une considération secondaire. Elle doit être intégrée dès la phase de conception. Un DFD est un excellent outil pour identifier les risques de sécurité en visualisant les endroits où les données sont exposées.
À chaque fois que les données passent d’un processus à un autre, une frontière de confiance est franchie. Dans un système moderne, cela peut aller d’une API publique à un microservice interne. Le DFD doit mettre en évidence ces frontières. Si un flux franchit une frontière sans chiffrement ni authentification, le diagramme révèle immédiatement une vulnérabilité.
Tous les flux de données n’ont pas le même poids. Les informations sensibles comme les données à caractère personnel (PII) nécessitent un traitement plus strict. Le diagramme peut utiliser un codage par couleur ou des icônes spécifiques pour indiquer les flux sensibles. Cela garantit que, lors de l’implémentation de la logique, les développeurs accordent la priorité au chiffrement et aux contrôles d’accès pour ces chemins précis.
Des réglementations comme le RGPD ou le HIPAA définissent comment les données doivent être stockées et déplacées. Un DFD moderne peut cartographier les flux de données aux exigences de conformité. Par exemple, un magasin de données pourrait être étiqueté « Région UE uniquement ». Si un processus extrait des données de ce magasin vers une autre région, le diagramme signale une violation potentielle de conformité. Cela permet aux architectes de corriger les problèmes avant d’écrire du code.
L’un des plus grands défis liés aux DFD est la maintenance. À mesure que le code évolue, le diagramme devient souvent obsolète. Les workflows modernes visent à combler cet écart grâce à l’automatisation.
Bien que les diagrammes entièrement automatisés ne soient pas encore parfaits, ils fournissent une base beaucoup plus proche de la réalité qu’un document statique créé il y a plusieurs mois. Cela maintient la documentation pertinente au fur et à mesure que le système évolue. 🔄
L’évolution des DFD est en cours. À mesure que la technologie progresse, les techniques de modélisation évoluent également.
Les modèles d’apprentissage automatique introduisent des flux non déterministes. Un processus peut produire des résultats différents en fonction de la probabilité plutôt que d’une logique fixe. Les DFD futurs pourraient avoir besoin de représenter séparément les intervalles de confiance ou les flux de données d’entraînement par rapport aux flux de données d’inférence. Cela ajoute une nouvelle dimension aux nœuds de stockage de données et de processus.
Les diagrammes statiques sont utiles pour la conception, mais que devient l’opération ? Les futures itérations pourraient relier les diagrammes à des tableaux de bord en direct. Si un flux de données est bloqué en production, la flèche correspondante sur le diagramme pourrait s’illuminer en rouge. Cela crée un document vivant qui reflète l’état actuel du système.
Il n’existe actuellement pas de standard universel pour représenter les événements dans les DFD. À mesure que l’industrie s’aligne sur des modèles d’événements spécifiques (comme CQRS ou Event Sourcing), un ensemble de symboles standardisé est susceptible d’émerger. Cela rendra les diagrammes interopérables entre différentes équipes et organisations.
Pour commencer à adapter vos pratiques actuelles de modélisation, suivez cette séquence générale.
Le diagramme de flux de données a survécu des décennies de changements technologiques parce que son objectif fondamental reste valide : la clarté. Bien que la notation doive s’adapter pour intégrer les microservices, l’infrastructure cloud et les événements asynchrones, l’objectif fondamental de visualiser le déplacement des données reste inchangé. En mettant à jour les symboles et le modèle mental derrière eux, les équipes peuvent continuer à utiliser les DFD comme outil principal d’analyse du système. L’évolution ne consiste pas à remplacer la méthode, mais à la perfectionner pour s’adapter à la complexité du paysage numérique moderne. 🌐