 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Les diagrammes de flux de données (DFD) sont des outils fondamentaux dans l’analyse et la conception des systèmes. Ils offrent une représentation visuelle du déplacement de l’information à travers un système. Comprendre la profondeur d’un DFD est essentiel pour s’assurer que les exigences sont correctement capturées. Ce guide explore le processus de passage d’un diagramme de contexte de haut niveau à un diagramme de niveau 1 détaillé. Nous examinerons les principes de décomposition, de conservation des données et d’intégrité structurelle sans dépendre d’outils logiciels spécifiques.
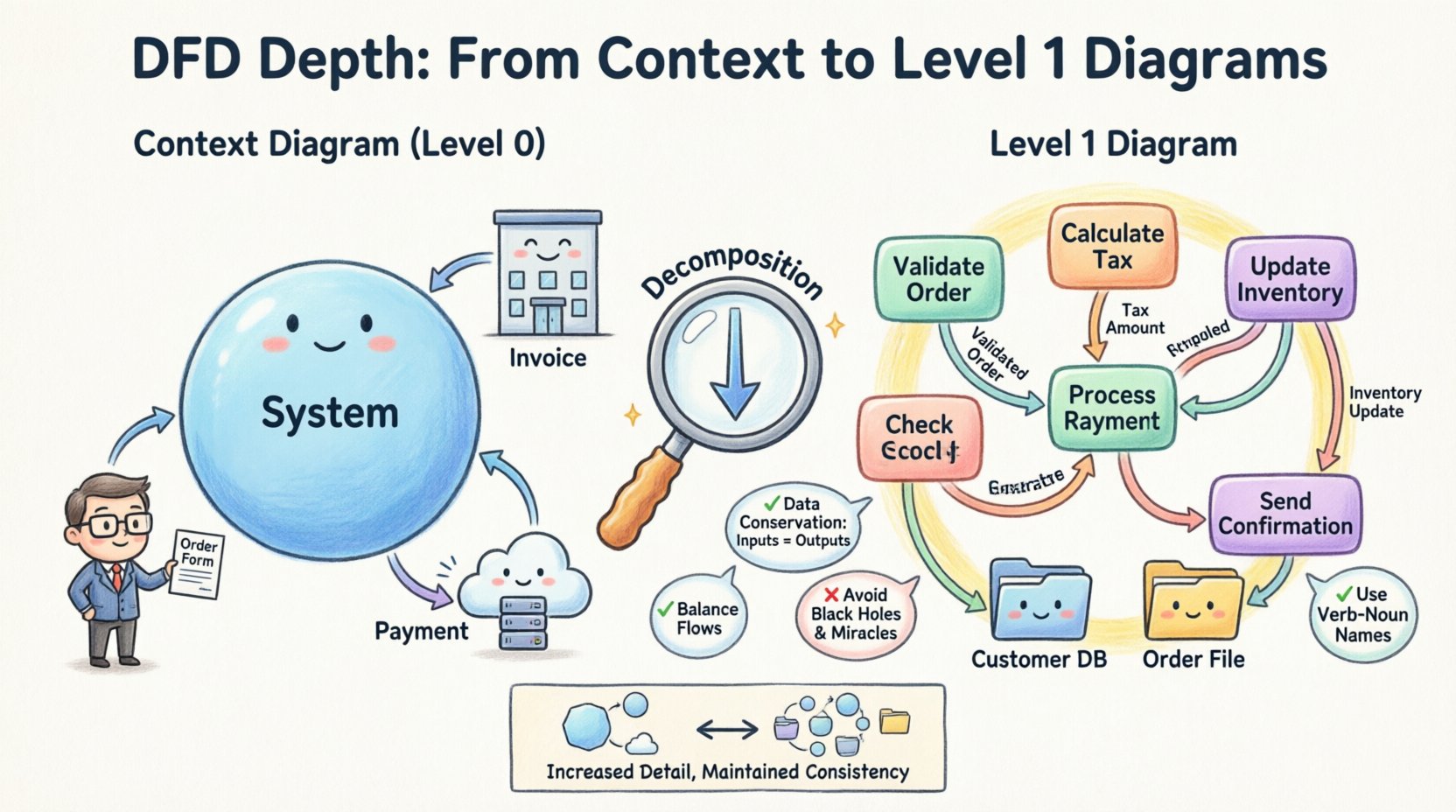
Les DFD ne sont pas des documents plats ; ils existent sous forme de hiérarchie. Cette structure permet aux analystes d’observer un système à différents niveaux de détail. Chaque niveau ajoute plus de précision aux processus et aux flux de données.
Le passage du diagramme de contexte au niveau 1 est souvent la étape la plus difficile pour les nouveaux analystes. Il faut trouver un équilibre entre la clarté et le détail. Si le diagramme est trop élevé, il manque d’informations exploitables. S’il est trop bas, il devient encombré et on perd de vue le tableau global.
Le diagramme de contexte sert d’ancrage pour l’ensemble de la suite des DFD. Il définit la frontière du système étudié. Tout ce qui est à l’intérieur du cercle fait partie du système ; tout ce qui est à l’extérieur est externe.
Établir la frontière est crucial. Une entité est externe si elle se trouve en dehors du périmètre du projet actuel. Par exemple, dans un système de paie, l’administration fiscale pourrait être une entité externe, mais le service financier pourrait être interne. Une mauvaise identification des frontières entraîne une extension du périmètre et de la confusion.
La décomposition est le processus de division d’un processus complexe en sous-processus plus petits et plus gérables. C’est le mécanisme fondamental pour créer un diagramme de niveau 1. Ce n’est pas seulement une question de fractionner des tâches ; c’est aussi une question de révéler la logique interne du système.
Lors du passage du niveau 0 au niveau 1, plusieurs règles doivent être respectées pour maintenir une cohérence logique.
L’une des exigences techniques les plus critiques est l’équilibre des flux de données. Les données entrant dans le processus de niveau 0 doivent être égales aux données entrant dans les processus de niveau 1. De même, les données sortant du processus de niveau 0 doivent être égales aux données sortant des processus de niveau 1.
Si le diagramme de contexte montre un « formulaire de commande » entrant dans le système, le diagramme de niveau 1 doit montrer ce même « formulaire de commande » entrant dans l’un des sous-processus. Si le diagramme de niveau 1 montre un « ID client » étant transmis internement, il ne peut pas être une entrée ou une sortie externe dans le diagramme de niveau 0, sauf s’il était déjà présent là.
Une fois le plan de décomposition prêt, la construction réelle commence. Cela implique d’identifier les principales zones fonctionnelles du système.
Regardez le processus unique du diagramme de contexte. Posez-vous la question : quelles sont les activités principales nécessaires pour remplir le but du système ? Ces activités deviennent les bulles ou cercles du diagramme de niveau 1.
Connectez les processus à l’aide de flèches. Ces flèches représentent le déplacement des données entre les processus internes. Vous pouvez également dessiner des flèches reliant les entités externes à ces nouveaux sous-processus.
Bien que les diagrammes de contexte les excluent, les diagrammes de niveau 1 les incluent fréquemment. Un magasin de données est un endroit où les données sont conservées au repos. Il peut s’agir d’une base de données, d’un fichier ou d’un classeur physique.
Lors de la représentation des magasins de données :
Même les analystes expérimentés commettent des erreurs lors de la création des diagrammes en flux de données. Reconnaître ces schémas tôt permet d’économiser du temps lors de la validation.
Un trou noir est un processus qui possède des entrées mais aucune sortie. Cela implique que les données sont consommées sans produire de résultat. Dans un système fonctionnel, chaque entrée doit entraîner une sortie ou un stockage de données.
Un miracle est un processus qui possède des sorties mais aucune entrée. Cela implique que les données sont générées à partir de rien. Chaque sortie doit être dérivée de données d’entrée.
Les diagrammes en flux de données suivent les flux de données, et non les flux de contrôle. Un flux de contrôle représente un signal pour démarrer ou arrêter un processus (par exemple, « Bouton Démarrer pressé »). Si vous voyez un flux qui ressemble à un signal de contrôle, il s’agit probablement en réalité de données (par exemple, « Demande de démarrage »). Les diagrammes en flux de données ne traitent pas explicitement le temps ou le contrôle logique.
Cela se produit lorsque les entrées du diagramme de niveau 1 ne correspondent pas aux entrées du diagramme de contexte. Vérifiez toujours la conservation des données après avoir dessiné le diagramme de niveau 1.
Le tableau suivant résume les différences entre les niveaux afin d’aider à comprendre quand utiliser lequel.
| Fonctionnalité | Diagramme de contexte (niveau 0) | Diagramme de niveau 1 |
|---|---|---|
| Processus central | Un seul processus | Plusieurs sous-processus |
| Magasins de données | Aucun | Oui, inclus |
| Niveau de détail | Résumé de haut niveau | Découpage fonctionnel |
| Entités externes | Toutes les entités principales | Sous-ensemble ou mêmes entités |
| Objectif principal | Définir le périmètre du système | Définir la logique interne |
Après le premier brouillon, le diagramme doit être validé. Ce n’est pas un simple contrôle ponctuel, mais un cycle de relecture et d’amélioration.
Au fur et à mesure que vous descendez dans la structure du DFD, vous devrez prendre des décisions concernant le niveau de détail. Jusqu’où devez-vous aller ?
Il n’existe pas de règle universelle, mais des lignes directrices générales existent :
Les magasins de données peuvent compliquer le flux visuel. Assurez-vous qu’ils soient placés de manière logique. Ne dessinez pas de ligne traversant un processus. Si une ligne doit traverser un processus, utilisez un point de connexion ou un symbole de jonction pour indiquer qu’elle le contourne, sans interaction.
Différenciez les acteurs à l’intérieur du système de ceux qui sont à l’extérieur. Si un opérateur humain fait partie du flux de travail du système (par exemple, un employé saisissant des données), il pourrait être un acteur interne, mais il est souvent représenté comme une entité externe car il se trouve à l’extérieur de la frontière logicielle. La cohérence dans cette définition est essentielle.
Le diagramme n’est que partie de l’histoire. Des descriptions textuelles sont nécessaires pour expliquer la logique.
Passer avec succès du contexte au niveau 1 exige une approche rigoureuse. Il ne s’agit pas de dessiner davantage de boîtes ; il s’agit de révéler la vérité du système.
En suivant ces étapes structurées, vous créez une base solide pour la conception du système. Le diagramme au niveau 1 devient le plan directeur pour les développeurs et un outil de communication pour les parties prenantes métier. Il comble le fossé entre les exigences abstraites et la mise en œuvre concrète.