 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Entrer dans le monde de l’ingénierie logicielle implique souvent de décrypter des plans complexes avant d’écrire une seule ligne de code. Parmi les divers diagrammes utilisés pour cartographier le comportement d’un système, le diagramme de flux de données (DFD) se distingue comme un outil essentiel pour comprendre comment les informations circulent à travers un système. Contrairement au code, qui dicte comment une tâche est effectuée, un DFD illustre quoi les données sont traitées et où elles se déplacent. Pour un nouvel ingénieur, la capacité à interpréter ces diagrammes se traduit directement par un onboarding plus rapide, une meilleure compréhension de l’architecture du système et une communication améliorée avec les parties prenantes.
Ce guide est conçu pour vous amener d’une compréhension basique des symboles à une capacité nuancée d’analyser des flux de processus complexes. Nous explorerons l’anatomie d’un DFD, la hiérarchie de ses niveaux, et les pièges courants qui indiquent des erreurs de modélisation. À la fin, vous disposerez d’un cadre pratique pour lire ces diagrammes avec confiance et précision.
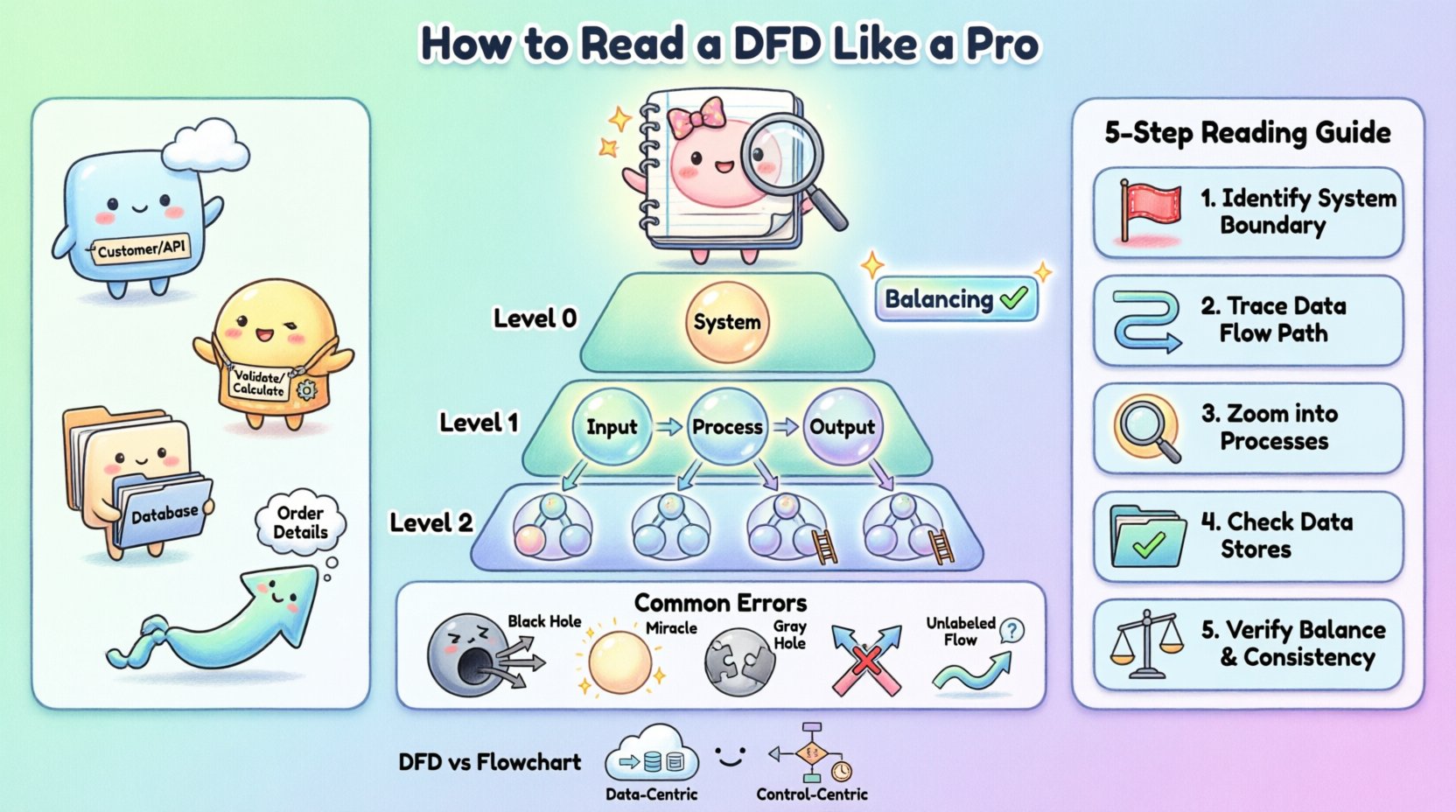
Un diagramme de flux de données est une représentation graphique du flux de données à travers un système d’information. Il modélise le système sous un angle fonctionnel, en se concentrant sur le déplacement des données plutôt que sur la logique de contrôle ou le temps. Cette distinction est essentielle. Alors qu’un diagramme de séquence montre l’ordre des événements, un DFD montre la transformation des données depuis l’entrée jusqu’à la sortie.
Quand vous regardez un DFD, vous regardez essentiellement une carte de la logique de votre système. Vous pouvez identifier :
D’où proviennent les données : Les sources externes ou entités.
Comment les données évoluent : Les processus qui transforment l’entrée en sortie.
Où les données sont stockées : Les magasins de données où les informations sont conservées.
Où les données aboutissent : Les destinations ou destinataires des informations traitées.
Comprendre ce but vous aide à éviter l’erreur courante de vouloir lire un DFD comme un organigramme. Il n’y a pas de boucle, pas de losange de décision, ni de séquence basée sur le temps dans un DFD standard. Il s’agit d’une capture statique du mouvement dynamique des données. Cette abstraction est puissante car elle permet aux ingénieurs de discuter des exigences du système sans s’enliser dans les détails d’implémentation.
Pour lire un DFD avec compétence, vous devez d’abord reconnaître ses quatre composants fondamentaux. Bien que les styles de notation varient légèrement selon les méthodologies, les concepts de base restent constants. Le tableau suivant décrit ces éléments et leurs représentations visuelles standard.
|
Composant |
Forme visuelle |
Fonction |
Exemple |
|---|---|---|---|
|
Entité externe |
Rectangle |
Source ou destination des données en dehors du système |
Client, Administrateur, API tierce |
|
Processus |
Cercle ou rectangle arrondi |
Transforme les données d’entrée en données de sortie |
Calculer la taxe, valider l’utilisateur |
|
Stockage de données |
Rectangle ouvert ou lignes parallèles |
Référentiel où les données sont stockées pour une utilisation ultérieure |
Base de données client, fichier journal |
|
Flux de données |
Flèche |
Direction et nom des données se déplaçant entre les composants |
Détails de la commande, confirmation de paiement |
Remarquez que les étiquettes sur ces composants ne sont pas arbitraires. La convention de nommage est essentielle pour la clarté. Un processus doit être nommé avec un verbe et un nom (par exemple, « Mettre à jour le stock »), indiquant une action effectuée sur les données. Un stockage de données doit représenter un nom (par exemple, « Journal du stock »), représentant une collection d’enregistrements. Les flux de données doivent être nommés pour décrire le contenu spécifique qui se déplace le long de la flèche.
Les systèmes complexes ne peuvent pas être représentés dans un seul diagramme sans devenir illisibles. Pour gérer la complexité, les diagrammes en flux de données sont structurés hiérarchiquement. Cette approche vous permet de zoomer dans et hors du système, en vous concentrant sur la logique de haut niveau ou sur les détails précis selon vos besoins.
Le diagramme de contexte fournit le niveau d’abstraction le plus élevé. Il représente le système sous la forme d’une seule bulle de processus et illustre comment il interagit avec des entités externes. Aucun stockage de données interne ni sous-processus n’est représenté ici. L’objectif est de définir les limites du système. Vous verrez le système au centre, entouré par les entités qui lui fournissent des données et reçoivent des données de lui. C’est le premier diagramme que vous devez consulter pour comprendre le périmètre du projet.
Également appelé diagramme de niveau supérieur, il divise la bulle système unique du diagramme de contexte en sous-systèmes majeurs ou en processus principaux. Il révèle les principaux stockages de données et le flux de données de haut niveau entre ces fonctions majeures. Ce niveau est essentiel pour comprendre les principaux modules du logiciel et leur interrelation.
Ces diagrammes représentent une décomposition supplémentaire. Un diagramme de niveau 1 détaille les processus indiqués dans le diagramme de niveau 0. Un diagramme de niveau 2 approfondit un processus spécifique du niveau 1. À mesure que vous descendez dans la hiérarchie, le nombre de processus et de stockages de données augmente. Toutefois, chaque processus individuel sur un diagramme de niveau inférieur doit être cohérent avec les entrées et sorties du processus parent sur le niveau supérieur.
Ce concept est connu sous le nom de équilibrage. Si un processus de niveau 0 a une entrée « Données de commande » et une sortie « Reçu », chaque processus enfant dans la décomposition doit collectivement rendre compte de la réception des « Données de commande » et de la production du « Reçu ». Cette cohérence est un indicateur clé d’un modèle bien construit.
Lorsqu’on vous remet un diagramme en flux de données pour une nouvelle fonctionnalité ou un système hérité, ne cherchez pas à mémoriser l’ensemble de l’image d’un coup. Utilisez plutôt une méthode de traçage systématique. Cela vous assure de ne pas manquer de connexions ni de mal interpréter la logique.
Étape 1 : Identifier les limites.Recherchez les entités externes. Ce sont les points de départ et d’arrivée. Demandez-vous : « Qui interagit avec ce système ? » Si un processus n’a aucune connexion à une entité externe ou à un stockage de données, il pourrait s’agir d’un composant isolé nécessitant une explication supplémentaire.
Étape 2 : Suivre le flux de données.Choisissez une entrée spécifique, par exemple une « Demande de connexion ». Suivez la flèche depuis l’entité vers le processus. Ensuite, suivez la flèche de sortie vers le processus suivant ou le stockage de données. Ne sautez pas d’un endroit à un autre du diagramme ; suivez un chemin à la fois.
Étape 3 : Analyser les processus. Pour chaque bulle de processus, demandez : « Quelle est la transformation ? » L’entrée correspond-elle logiquement à la sortie ? Par exemple, si un processus est nommé « Calculer la remise », assurez-vous que les entrées incluent « Prix » et « Statut d’adhésion ». Si les entrées manquent, le schéma est incomplet.
Étape 4 : Vérifier les magasins de données. Assurez-vous qu’il existe au moins une opération de lecture (flux d’entrée) et une opération d’écriture (flux de sortie) pour chaque magasin de données, sauf s’il s’agit d’un enregistrement permanent mis à jour occasionnellement. Un magasin de données qui reçoit uniquement des données sans jamais les libérer pourrait être une erreur de type « puits », tandis qu’un magasin qui ne libère que des données pourrait être une erreur de type « source ».
Étape 5 : Vérifier l’équilibre. Si vous examinez un schéma de niveau 1, vérifiez-le par rapport à son schéma parent de niveau 0. Les entrées et sorties correspondent-elles ? Si le processus parent indique « Recevoir une commande », le processus enfant doit également recevoir des données « Commande ». Si le processus enfant reçoit plutôt « Paiement », le schéma est déséquilibré.
En suivant cette séquence, vous passez de la vue d’ensemble à la vue détaillée, garantissant une compréhension complète de l’architecture du système.
Même les ingénieurs expérimentés commettent des erreurs lors de la création de diagrammes de flux de données. En tant que lecteur, repérer ces anomalies peut vous faire gagner un temps considérable pendant le développement. Reconnaître ces erreurs vous aide à poser les bonnes questions aux architectes du système.
Un trou noir se produit lorsqu’un processus possède des entrées mais aucune sortie. Les données entrent dans le processus et disparaissent. Dans un système réel, cela implique une perte de données. Par exemple, si un « Traitement utilisateur » reçoit un « Formulaire de connexion » mais ne produit aucune sortie vers une base de données ou une page de confirmation, les données n’ont nulle part où aller. Cela indique une exigence manquante ou un chemin logique brisé.
Un miracle est l’inverse d’un trou noir. Il s’agit d’un processus qui produit des sorties sans recevoir d’entrées. Comment un système peut-il générer un « Rapport de ventes » sans lire les « Données de ventes » ? Cela suggère que les données sont générées de nulle part, ce qui est impossible dans un système déterministe. L’entrée manquante doit être identifiée et connectée à un magasin de données ou à une entité externe.
Cette erreur se produit lorsque les entrées et sorties d’un processus ne correspondent pas logiquement, même si les deux existent. Par exemple, si un processus est nommé « Calculer la taxe » mais que l’entrée est « Adresse utilisateur » et que la sortie est « Prix total », la transformation est incomplète. Le taux de taxe est manquant. Cela indique souvent un magasin de données manquant ou un flux non connecté.
Dans les diagrammes de flux de données propres, les flèches ne doivent pas se croiser sans connexion. Si deux flux de données se croisent, il peut être ambigu de savoir s’ils interagissent ou simplement se croisent. Bien qu’un certain croisement soit inévitable dans les diagrammes complexes, cela indique un mauvais agencement. Dans un diagramme bien conçu, les flux doivent être acheminés clairement pour éviter toute confusion.
Chaque flèche doit être étiquetée. Une flèche sans nom implique que le contenu spécifique des données est inconnu. Si vous voyez une flèche reliant un magasin de données à un processus, vous devez savoir quelles données sont récupérées. « Données » n’est pas une étiquette suffisamment précise. Elle devrait être « Liste des clients » ou « Jetons de session actifs ». Les étiquettes ambiguës sont une source majeure d’erreurs d’implémentation.
L’un des points les plus fréquents de confusion pour les nouveaux ingénieurs est la différence entre un diagramme de flux de données et un diagramme de flux. Bien qu’ils utilisent tous deux des formes et des flèches, leurs significations sont fondamentalement différentes.
Focus : Un diagramme de flux se concentre sur le flux de contrôle. Il montre la séquence des opérations, les points de décision (si/sinon) et les boucles. Il répond à la question « Qu’est-ce qui arrive ensuite ? » Un DFD se concentre sur le flux de données. Il montre le déplacement de l’information. Il répond à la question « Où vont les données ? »
Logique vs. Données : Dans un diagramme de flux, vous verrez des losanges de décision. Dans un DFD standard, ce n’est pas le cas. Un DFD suppose que le processus a lieu ; il ne modélise pas la logique de branchement de ce processus.
Temps : Les diagrammes de flux impliquent souvent une séquence temporelle. Les DFD sont généralement sans temps. Un DFD ne montre pas quel processus se produit en premier, sauf si cela est implicite par les dépendances des données.
Stockage :Les diagrammes de flux ne montrent généralement pas de manière explicite le stockage des données. Les DFD modélisent explicitement les magasins de données comme un composant central.
Comprendre cette distinction vous empêche de chercher une logique de contrôle là où il n’y en a pas. Si vous cherchez la logique « si cela, alors cela », consultez un diagramme de flux ou du pseudo-code. Si vous cherchez où la base de données est mise à jour, regardez le DFD.
Lire les DFD n’est pas seulement un exercice académique ; c’est une exigence quotidienne pour les ingénieurs logiciels. Voici comment cette compétence se traduit dans des scénarios du monde réel.
1. Intégration et revue de code : Lorsque vous rejoignez une nouvelle équipe, la documentation d’architecture inclut souvent des DFD. Les lire vous permet de comprendre les dépendances des données avant de toucher au code. Lors des revues de code, vous pouvez vérifier si l’implémentation correspond au diagramme. Si le diagramme montre des données allant vers un cache, mais que le code écrit uniquement dans la base de données, vous avez identifié une incohérence.
2. Débogage et dépannage : Lorsqu’une fonctionnalité est défaillante, un DFD vous aide à suivre le parcours des données. Si un utilisateur signale que son profil n’est pas mis à jour, vous pouvez suivre le flux « Mettre à jour le profil » sur le DFD. Vous pouvez vérifier quels processus sont impliqués et quels magasins de données sont consultés. Cela réduit considérablement l’espace de recherche par rapport à une recherche aveugle dans le code.
3. Recueil des exigences : En travaillant avec les gestionnaires de produits, vous devez souvent visualiser les exigences. Si vous comprenez les DFD, vous pouvez aider à affiner ces exigences. Vous pouvez repérer des flux de données manquants ou des transformations impossibles avant le début du développement. Cette approche proactive réduit la dette technique.
4. Intégration système : Dans les architectures de microservices, les DFD sont essentiels pour définir les contrats d’API. Vous pouvez cartographier les flux de données entre les services pour garantir que la sortie du service A est compatible avec l’entrée du service B. Cela évite les échecs d’intégration dus à des formats de données incompatibles.
Pour garantir que les diagrammes que vous lisez restent utiles dans le temps, considérez les pratiques suivantes. Un diagramme obsolète est pire qu’aucun diagramme.
Gardez-le de haut niveau : N’embouteillez pas un DFD avec chaque nom de variable. Restez sur des entités logiques de données. « Entrée utilisateur » est préférable à « Valeur du champ Nom ».
Utilisez une nomenclature cohérente : Assurez-vous que « Client » dans un diagramme est appelé « Client » dans tous les diagrammes connexes. Évitez les synonymes comme « Client » ou « Utilisateur » sauf s’ils font référence à des entités différentes.
Mettez à jour lors des modifications : Si le code change de manière significative, le DFD doit être mis à jour. Un diagramme contrôlé en version peut servir d’historique de l’évolution du système.
Limitez la complexité : Si un seul diagramme devient trop encombré, il est temps de le décomposer en diagrammes de niveau inférieur. Une bonne règle empirique est qu’un diagramme de niveau 0 ne devrait pas comporter plus de 7 à 10 processus majeurs.
Maîtriser l’interprétation des diagrammes de flux de données exige de la patience et de la pratique. Cela consiste à aller au-delà des symboles pour comprendre les relations logiques entre eux. En vous concentrant sur le déplacement des données, en identifiant les anomalies et en comprenant la hiérarchie, vous vous munissez d’un outil puissant pour l’analyse des systèmes.
Au fur et à mesure que vous progressez dans votre carrière d’ingénieur, vous rencontrerez diverses techniques de modélisation. Le DFD reste une compétence fondamentale. Il vous apprend à penser les systèmes en termes d’entrées, de transformations et de sorties. Ce mode de pensée est transférable à la conception de bases de données, à l’architecture d’API et à la planification d’infrastructures cloud. Continuez à pratiquer la lecture de ces diagrammes dans des projets open source ou dans la documentation interne. Plus vous suivrez les flux, plus l’architecture du système deviendra intuitive.