 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Les diagrammes de flux de données (DFD) constituent un outil fondamental dans l’analyse et la conception de systèmes. Ils offrent une représentation visuelle du déplacement de l’information à travers un système, en mettant en évidence les entrées, les sorties, le stockage et les processus. Pour les débutants, comprendre le fonctionnement d’un DFD est essentiel avant d’essayer de représenter des flux de travail complexes. Ce guide explore les principes fondamentaux, les composants et les règles nécessaires pour construire des diagrammes précis sans dépendre d’outils logiciels spécifiques.
Un diagramme de flux de données est une technique d’analyse structurée utilisée pour visualiser le déplacement des données au sein d’un système. Contrairement à un organigramme, qui se concentre sur la logique de contrôle et les points de décision, un DFD se concentre strictement sur le déplacement des données. Il répond à la question : D’où provient les données, où vont-elles et que leur arrive-t-il ?
Les objectifs principaux de l’utilisation d’un DFD incluent :
Lorsque vous commencez à analyser un système, l’objectif est de créer un modèle que les parties prenantes peuvent comprendre. Un diagramme bien construit élimine toute ambiguïté concernant la gestion des données. Il agit comme un plan directeur pour les développeurs et les analystes, garantissant que tout le monde est d’accord sur la manière dont les informations circulent.
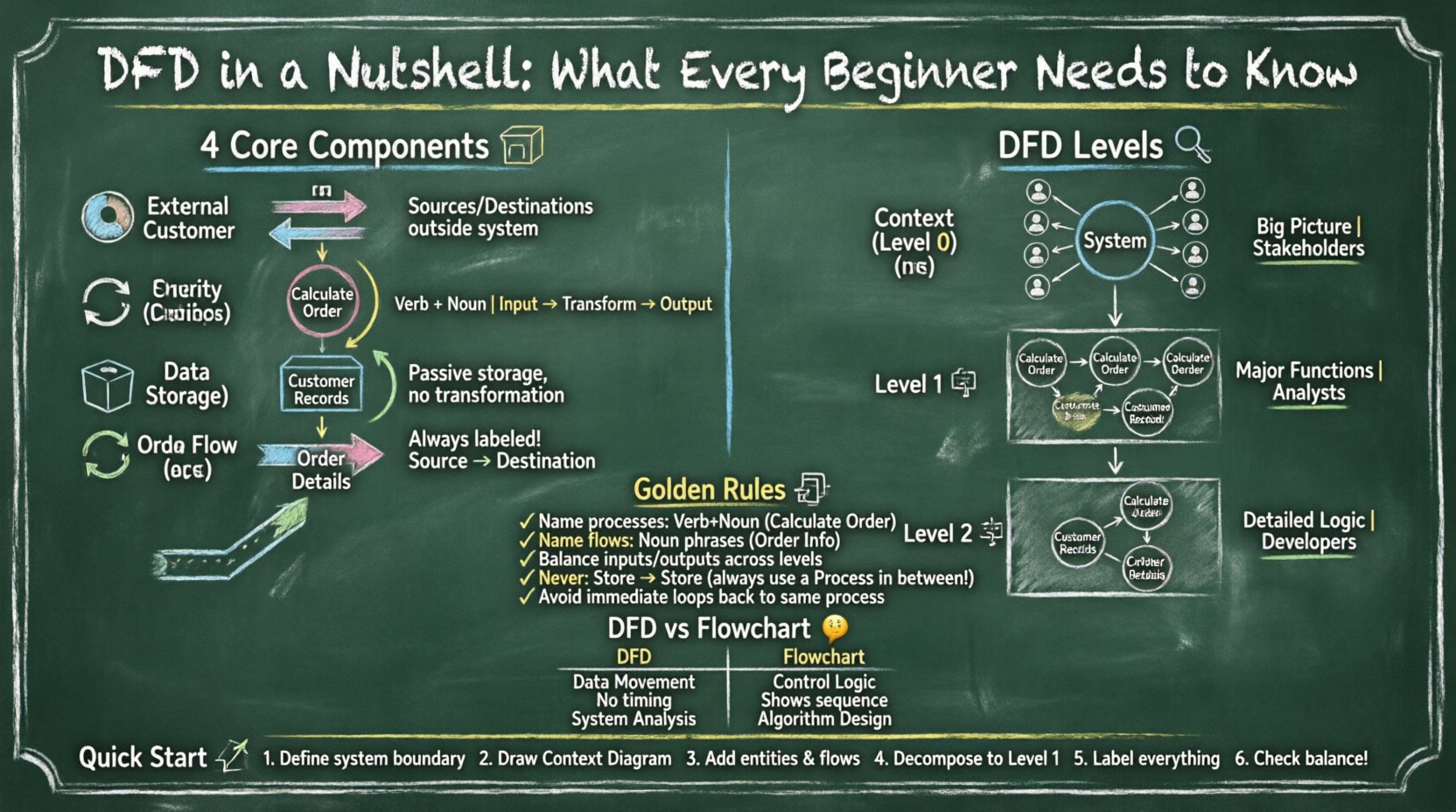
Pour dessiner un diagramme valide, vous devez comprendre les quatre formes fondamentales et leur signification. Ces composants forment le vocabulaire de la modélisation du flux de données. Chaque élément a un rôle spécifique dans l’architecture du système.
Les entités externes représentent les sources ou les destinations des données situées à l’extérieur du système modélisé. Elles sont également appelées terminaisons ou agents. Ces entités interagissent avec le système mais ne font pas partie de sa logique interne.
Une entité doit être externe. Si l’entité fait partie de la logique interne du système, elle doit être représentée comme un processus. Cette confusion conduit souvent à des définitions incorrectes des limites du système.
Les processus sont des actions qui transforment les données d’entrée en données de sortie. Ils représentent le travail effectué, les calculs ou la logique de prise de décision à l’intérieur du système. Un processus modifie l’état ou le contenu des données.
Chaque processus doit avoir au moins une entrée et une sortie. Un processus qui n’a que des entrées sans sortie, ou seulement des sorties sans entrée, est invalide. Cela est connu comme un trou noir ou un miracle, respectivement.
Les magasins de données sont des lieux où les informations sont conservées pour une utilisation ultérieure. Ils ne transforment pas les données ; ils les stockent simplement. Cela peut être une base de données, un fichier, un classeur physique ou même une zone de stockage temporaire.
Les flux de données peuvent entrer et sortir d’un magasin de données, mais le magasin lui-même ne modifie pas les données. Il agit comme un répertoire passif. Dans les systèmes modernes, cela correspond souvent à une table de base de données.
Les flux de données représentent le déplacement des données entre des entités, des processus et des magasins. Ils indiquent la direction du transfert d’information. Un flux de données doit toujours être étiqueté pour indiquer précisément quelles informations sont en mouvement.
Un flux de données ne peut exister sans source ni destination. Il ne peut pas flotter dans les airs. En outre, les flux de données ne doivent pas se croiser sans point d’intersection spécifique, bien que certaines notations permettent cela pour simplifier.
Les systèmes complexes ne peuvent pas être représentés sur une seule page. Pour gérer la complexité, les diagrammes de flux de données sont divisés en niveaux. Cette technique s’appelle décomposition. Il vous permet de zoomer sur des zones spécifiques tout en conservant une vue d’ensemble.
Le diagramme de contexte est la vue de niveau le plus élevé. Il représente l’ensemble du système comme un seul processus. Il identifie le nom du système ainsi que toutes les entités externes interagissant avec lui. Aucun stockage de données ni processus internes n’est représenté dans cette vue.
Le diagramme Niveau 1 éclate le processus unique du diagramme de contexte en sous-processus majeurs. Il révèle les principales zones fonctionnelles du système. Il s’agit souvent du premier diagramme détaillé créé.
Les diagrammes Niveau 2 décomposent davantage des processus spécifiques du Niveau 1. Si un processus du Niveau 1 est complexe, il est étendu en plusieurs sous-processus au Niveau 2. Ce processus se poursuit jusqu’à ce que les processus soient suffisamment simples pour être directement mis en œuvre.
| Niveau | Focus | Nombre de processus | Public cible principal |
|---|---|---|---|
| Contexte | Frontière du système | 1 | Gestion, parties prenantes |
| Niveau 1 | Fonctions principales | 3 à 7 | Analystes, concepteurs |
| Niveau 2 | Sous-fonctions | Variable | Développeurs, implémenteurs |
Créer un diagramme de flux de données ne consiste pas seulement à dessiner des lignes ; il s’agit de respecter des règles logiques. Violenter ces règles entraîne des diagrammes incorrects sur le plan technique et confus. Respecter les conventions standard garantit une cohérence dans la documentation.
Chaque élément doit être clairement nommé afin d’éviter toute ambiguïté. Une mauvaise nomination est l’erreur la plus fréquente dans les diagrammes débutants.
La cohérence dans la nomenclature permet aux lecteurs de suivre les données à travers plusieurs niveaux du diagramme sans confusion.
L’équilibre est une règle essentielle lors du passage d’un niveau à un autre. Les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties du diagramme enfant créé par sa décomposition.
Vérifiez toujours les flèches entrant et sortant de la frontière d’un processus décomposé par rapport au processus parent.
Les flux de données entrent et sortent des magasins de données. Toutefois, un flux de données ne peut pas aller directement d’un magasin de données à un autre sans qu’un processus ne se trouve entre les deux. Un processus doit agir comme intermédiaire pour transformer ou acheminer les données.
Cette règle garantit que les données ne sont pas simplement déplacées sans raison. Chaque déplacement doit impliquer une logique ou une action spécifique.
Les boucles while sont courantes en programmation, mais dans les diagrammes de flux de données (DFD), elles peuvent indiquer un défaut de conception. Un flux de données ne doit pas revenir immédiatement au même processus sans passer par d’autres composants. Si un flux revient, cela implique un délai ou la nécessité d’un processus différent.
Les débutants confondent souvent les diagrammes de flux de données avec les organigrammes. Bien que les deux utilisent des formes similaires comme des boîtes et des flèches, leurs objectifs sont fondamentalement différents.
| Fonctionnalité | Diagramme de flux de données (DFD) | Organigramme |
|---|---|---|
| Focus | Déplacement des données | Logique de contrôle |
| Points de décision | Non affichés explicitement | Composant central (forme de losange) |
| Processus | Transformation des données | Séquence des étapes |
| Temps | Ne montre pas la séquence | Montre la séquence et le timing |
| Contexte | Analyse du système | Algorithme ou procédure |
Si vous devez montrer ce qui arrive aux données, utilisez un DFD. Si vous devez montrer comment le système décide ce qu’il doit faire ensuite, utilisez un organigramme. Utiliser un DFD pour représenter la logique de contrôle conduit souvent à des diagrammes encombrés et illisibles.
Une fois que vous avez compris la théorie, l’application pratique suit une séquence logique. Vous n’avez pas besoin de logiciels coûteux pour commencer ; le papier et le crayon fonctionnent tout aussi bien pour les premiers croquis.
Même les analystes expérimentés commettent des erreurs. Être conscient des erreurs courantes peut faire gagner beaucoup de temps pendant la phase de revue.
Les diagrammes de flux de données ne conviennent pas à toutes les situations. Comprendre le contexte approprié pour leur utilisation est essentiel pour une documentation efficace.
Un diagramme de flux de données n’est pas un livrable unique. Les systèmes évoluent, et vos diagrammes doivent évoluer aussi. L’entretien consiste à maintenir la documentation synchronisée avec le logiciel réel.
En maintenant des diagrammes précis, vous réduisez le risque d’erreurs lors des mises à jour futures. Un diagramme obsolète est souvent pire qu’aucun diagramme, car il induit en erreur l’équipe de développement.
Les diagrammes de flux de données sont un outil puissant pour visualiser le comportement du système. Ils se concentrent sur le déplacement des données plutôt que sur la logique de contrôle. En maîtrisant les quatre composants fondamentaux — Entités externes, Processus, Stockages de données et Flux de données —, vous pouvez créer des modèles clairs et efficaces. N’oubliez pas de décomposer les systèmes complexes en niveaux, de respecter des conventions de nommage strictes et de suivre la règle d’équilibre. Évitez les pièges courants tels que les flux fantômes et la logique de contrôle. Avec de la pratique, vous serez en mesure de cartographier des systèmes d’information complexes avec confiance et clarté.