 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











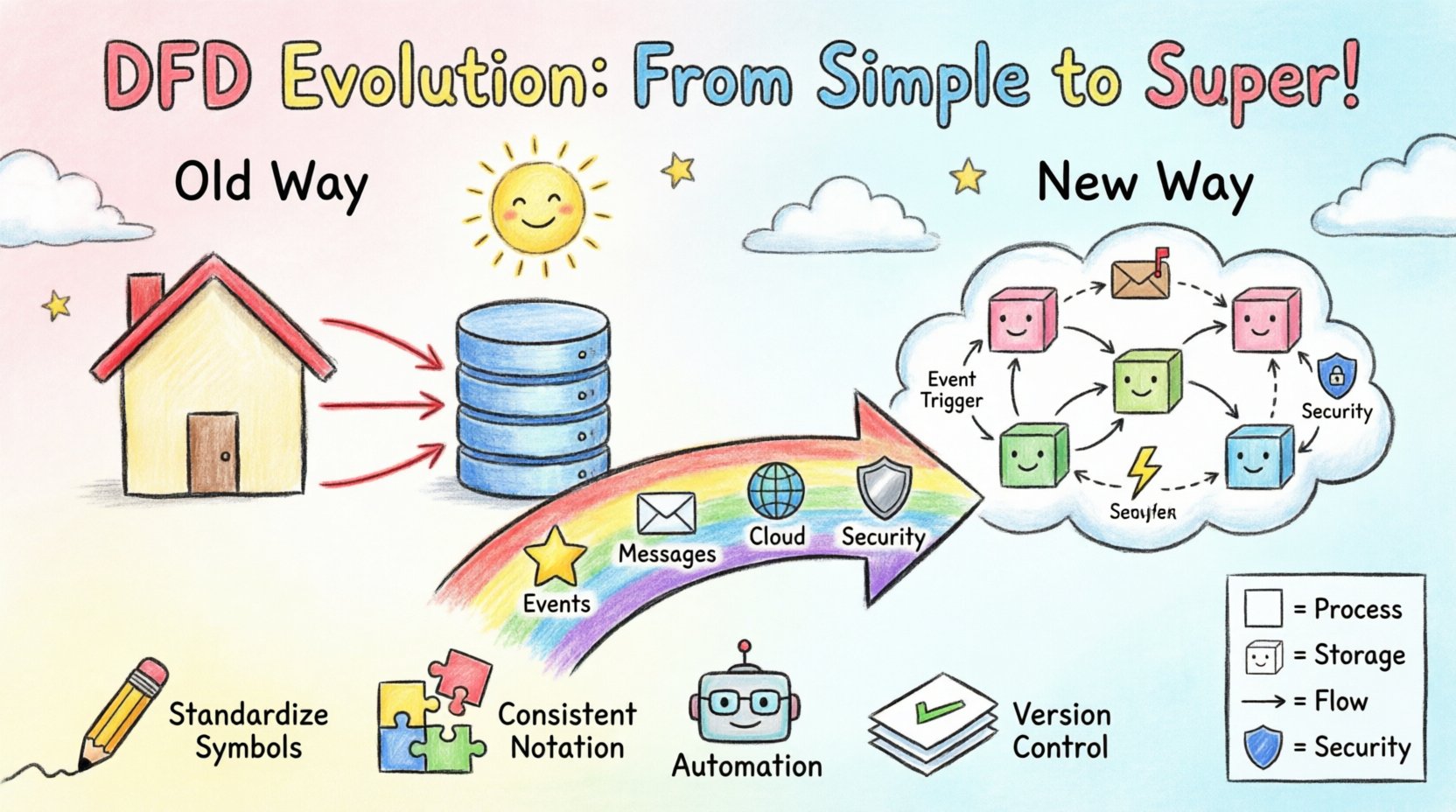
El análisis de sistemas ha contado durante mucho tiempo con representaciones visuales para comunicar lógica compleja. El diagrama de flujo de datos (DFD) sigue siendo una piedra angular de esta práctica. Sin embargo, el panorama de la arquitectura de software ha cambiado drásticamente. Hemos pasado de aplicaciones monolíticas a microservicios distribuidos, de bases de datos locales a almacenamiento nativo en la nube, y de solicitudes síncronas a flujos de eventos asíncronos. El DFD tradicional, diseñado para procesos más simples y lineales, enfrenta nuevos desafíos en estos entornos. Esta guía explora cómo evoluciona la metodología para mantenerse relevante, asegurando una modelización precisa sin volverse obsoleta. 🛠️
Antes de examinar la evolución, es necesario establecer la base. Un DFD estándar visualiza el flujo de información a través de un sistema. Se centra en qué lo que hace el sistema, no en cómo lo hace. Esta distinción separa la modelización de procesos del diseño estructural. Los componentes principales permanecen consistentes a través de las generaciones:
En el contexto tradicional, estos diagramas eran jerárquicos. Un diagrama de contexto proporcionaba una vista de alto nivel (nivel 0), que luego se descomponía en diagramas detallados de nivel 1 y nivel 2. Esto funcionaba bien cuando un sistema tenía un inicio y un final claros, y los datos se movían de forma predecible desde la entrada hasta la salida. Sin embargo, los sistemas modernos a menudo carecen de un único punto de entrada o de una salida definitiva. Los datos entran y salen continuamente, a menudo en tiempo real. 🔄
La transición de los monolitos a sistemas distribuidos introduce fricción en la modelización estática. En una aplicación monolítica, una transacción de base de datos podría desencadenar una serie de llamadas a funciones que se completan de inmediato. Un DFD podría dibujar una línea recta desde la base de datos hasta el proceso y luego hasta la salida. En un entorno de microservicios, la situación es mucho más compleja.
Los sistemas modernos dependen con frecuencia de brokers de mensajes y colas. Una solicitud se recibe, se almacena en una cola y luego se procesa más tarde por un trabajador. Los DFD tradicionales tienen dificultades para representar el tiempo. Implican un flujo inmediato. Una flecha estática no transmite fácilmente que los datos podrían permanecer en un búfer durante horas antes de que el siguiente proceso se active. Esto genera ambigüedad en el análisis del comportamiento del sistema.
Las arquitecturas en la nube a menudo utilizan contenedores sin estado que se inician y detienen. Un DFD suele implicar un proceso permanente. Cuando un proceso es efímero, el diagrama debe aclarar dónde se almacena el estado (el almacén de datos) frente a dónde reside la lógica (el cálculo). Si el diagrama no distingue entre ambos, los desarrolladores podrían asumir incorrectamente que el estado se mantiene dentro del proceso mismo, lo que genera errores.
Los modelos antiguos trataban los almacenes de datos como cajas genéricas. El cumplimiento moderno requiere comprender dónde reside geográficamente los datos y cómo se cifran. Un DFD ahora debe indicar la soberanía de datos y los niveles de seguridad. Si un flujo de datos cruza una zona de seguridad, el diagrama debe reflejar esa frontera, no solo la conexión lógica.
Para abordar estas brechas, los profesionales están modificando la notación estándar para adaptarla a la arquitectura orientada a eventos (EDA). El concepto central sigue siendo el flujo de datos, pero los desencadenantes cambian.
Esta adaptación requiere un cambio de perspectiva. El diagrama ya no es solo un mapa del sistema; es un mapa de los incidentesque impulsan el sistema. Ayuda a los interesados a comprender el ciclo de vida de un conjunto de datos desde su creación hasta su consumo final, incluidos los periodos de pausa entre ellos. 🕒
A medida que las aplicaciones se trasladan a la nube, el DFD debe alinearse con los contratos de API y los límites de los servicios. El diagrama sirve como puente entre los requisitos del negocio y la implementación técnica.
La mayoría de los sistemas modernos exponen una pasarela de API. En un DFD, esto reemplaza a la entidad externa genérica. La pasarela se convierte en un proceso específico encargado del enrutamiento, autenticación y control de tasa. El diagrama debe mostrar la transformación de la solicitud entrante en un comando interno. Esto aclara la separación de responsabilidades.
En bases de datos distribuidas, los datos a menudo se fragmentan. Un símbolo tradicional de almacén de datos es insuficiente. El diagrama debe indicar que un proceso podría consultar múltiples fragmentos para armar una respuesta. Esto visualiza la complejidad de las operaciones de lectura frente a las de escritura. Por ejemplo, una escritura podría ir a una sola partición, mientras que una lectura agrega datos de tres.
Los servicios a menudo no conocen la dirección de red de otros servicios en tiempo de diseño. Los descubren en tiempo de ejecución. Un DFD puede representar esto utilizando un nodo de “Registro de servicios”. Los procesos se conectan al registro para encontrar la ubicación actual de un servicio dependiente. Esto añade una capa de visibilidad de la infraestructura al flujo lógico.
Comprender las diferencias ayuda a los equipos a elegir el nivel adecuado de abstracción. La siguiente tabla describe las principales diferencias en cómo se construyen y interpretan los DFD hoy en día frente al pasado.
| Característica | DFD tradicional | DFD moderno |
|---|---|---|
| Dirección del flujo | Síncrono, inmediato | Asíncrono, con retraso o por lotes |
| Naturaleza del proceso | Monolítico, de larga duración | Microservicio, efímero, sin estado |
| Almacenamiento | Base de datos centralizada | Fragmentado, distribuido o almacenamiento de objetos |
| Disparadores | Llegada de datos de entrada | Eventos, mensajes o tareas programadas |
| Límites | Perímetro del sistema | Zonas de seguridad y pasarelas de API |
| Concurrencia | A menudo ignorado | Modelado explícitamente (colas, bloqueos) |
A medida que los diagramas se vuelven más complejos, la legibilidad se convierte en un riesgo. Las siguientes prácticas garantizan que el DFD siga siendo una herramienta útil y no un artefacto confuso.
La seguridad ya no es una consideración posterior. Debe integrarse en la fase de diseño. Un DFD es una excelente herramienta para identificar riesgos de seguridad al visualizar dónde los datos están expuestos.
Cada vez que los datos pasan de un proceso a otro, se cruza un límite de confianza. En un sistema moderno, esto podría ser desde una API pública hasta un microservicio interno. El DFD debe resaltar estos límites. Si un flujo cruza un límite sin cifrado ni autenticación, el diagrama revela inmediatamente una vulnerabilidad.
No todos los flujos de datos tienen la misma importancia. La información sensible como la PII (información personal identificable) requiere un manejo más estricto. El diagrama puede usar codificación por colores o íconos específicos para indicar flujos sensibles. Esto garantiza que cuando los desarrolladores implementen la lógica, prioricen el cifrado y los controles de acceso para esos caminos específicos.
Regulaciones como el GDPR o el HIPAA indican cómo deben almacenarse y moverse los datos. Un DFD moderno puede mapear flujos de datos a requisitos de cumplimiento. Por ejemplo, un almacén de datos podría etiquetarse como «Solo región de la UE». Si un proceso extrae datos de este almacén hacia otra región, el diagrama señala una posible violación de cumplimiento. Esto permite a los arquitectos corregir los problemas antes de escribir código.
Uno de los mayores desafíos con los DFD es el mantenimiento. A medida que cambia el código, el diagrama a menudo se vuelve obsoleto. Las prácticas modernas buscan cerrar esta brecha mediante la automatización.
Aunque los diagramas completamente automatizados aún no son perfectos, proporcionan una base mucho más cercana a la realidad que un documento estático creado hace meses. Esto mantiene la documentación relevante mientras el sistema evoluciona. 🔄
La evolución de los DFD está en curso. A medida que avanza la tecnología, también lo hacen las técnicas de modelado.
Los modelos de aprendizaje automático introducen flujos no deterministas. Un proceso podría producir resultados diferentes basados en probabilidades en lugar de lógica fija. Los DFD futuros podrían necesitar representar intervalos de confianza o flujos de datos de entrenamiento por separado de los flujos de datos de inferencia. Esto añade una nueva dimensión a los nodos de almacén de datos y procesos.
Los diagramas estáticos son útiles para el diseño, pero ¿qué hay de las operaciones? Las futuras iteraciones podrían vincular diagramas con paneles en vivo. Si un flujo de datos se bloquea en producción, la flecha correspondiente en el diagrama podría iluminarse en rojo. Esto crea un documento vivo que refleja el estado actual del sistema.
Actualmente no existe una norma universal para representar eventos en los DFD. A medida que la industria se alinee con patrones específicos de eventos (como CQRS o Event Sourcing), es probable que surja un conjunto estandarizado de símbolos. Esto hará que los diagramas sean interoperables entre diferentes equipos y organizaciones.
Para comenzar a adaptar sus prácticas actuales de modelado, siga esta secuencia general.
El Diagrama de Flujo de Datos ha sobrevivido décadas de cambios tecnológicos porque su propósito central sigue siendo válido: la claridad. Aunque la notación debe adaptarse para acomodar microservicios, infraestructura en la nube y eventos asíncronos, el objetivo fundamental de visualizar el movimiento de datos permanece inalterado. Al actualizar los símbolos y el modelo mental detrás de ellos, los equipos pueden seguir utilizando los DFD como herramienta principal para el análisis del sistema. La evolución no consiste en reemplazar el método, sino en perfeccionarlo para adaptarse a la complejidad del entorno digital moderno. 🌐