Die Gestaltung eines komplexen Softwaresystems erfordert eine klare Karte, wie Daten fließen und wo sie sich befinden. Ohne einen strukturierten Ansatz können Architekturen brüchig werden, schwer zu pflegen sind und anfällig für logische Fehler. Zwei der grundlegendsten Modellierungstechniken in der Systemtechnik sind das Datenflussdiagramm (DFD) und das Entitäts-Beziehungs-Diagramm (ERD). Obwohl beide eine entscheidende Funktion der Visualisierung erfüllen, behandeln sie grundlegend unterschiedliche Aspekte des Systems.
Das Verständnis des Unterschieds zwischen diesen beiden Modellen ist keine bloße akademische Übung; es ist eine praktische Notwendigkeit für Systemarchitekten, Geschäftsanalysten und Entwickler. Die Verwendung des falschen Modells in der falschen Entwicklungsphase kann zu Missverständnissen, Datenbank-Ineffizienzen oder beschädigtem Geschäftslogik führen. Dieser Leitfaden untersucht die Feinheiten jeder Diagrammart, ihre spezifischen Komponenten sowie die strategischen Szenarien, in denen eine Methode gegenüber der anderen Vorrang hat.
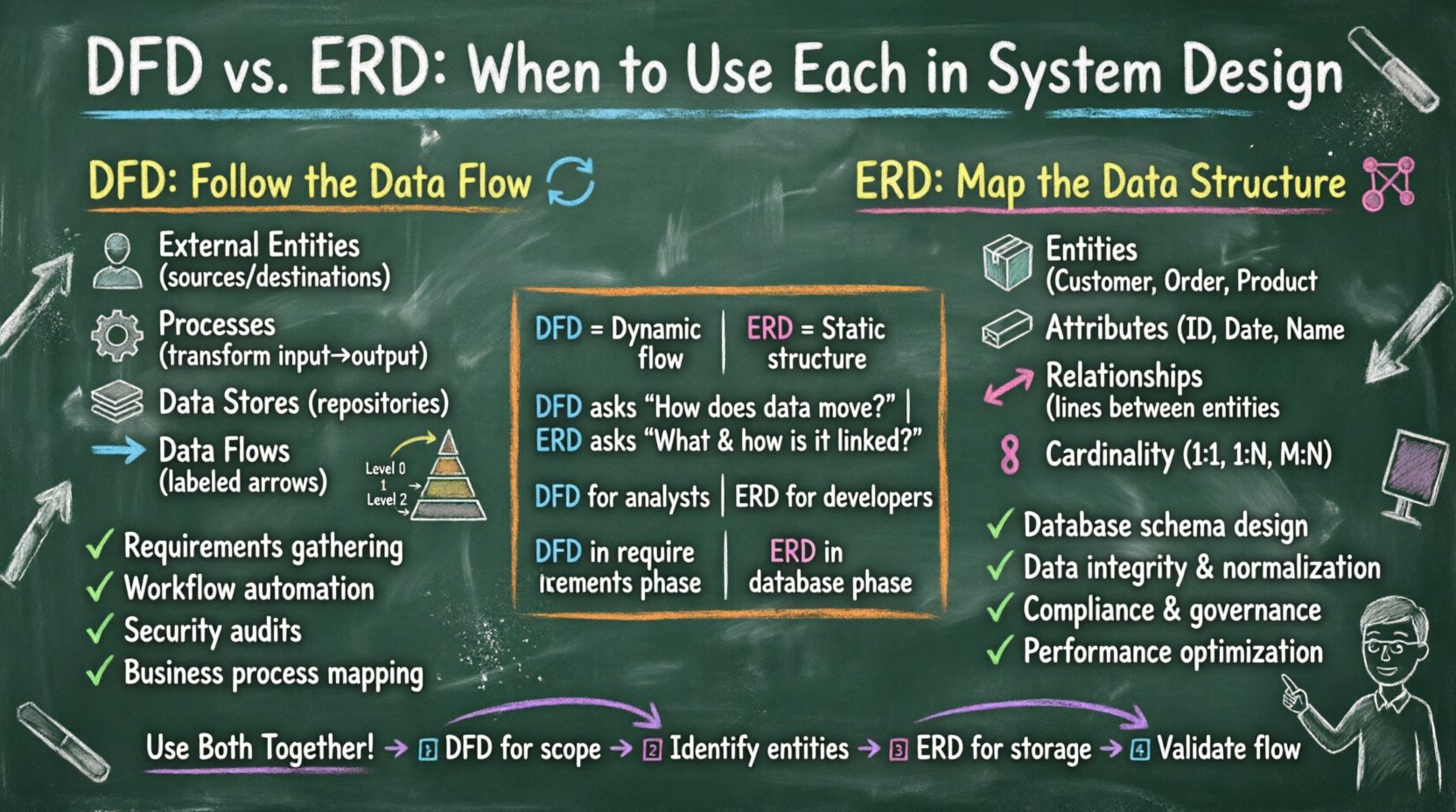
Verständnis des Datenflussdiagramms (DFD) 🔄
Das Datenflussdiagramm konzentriert sich auf die Bewegung von Daten durch ein System. Es visualisiert, wie Informationen verarbeitet, transformiert und gespeichert werden. Das DFD beschäftigt sich nicht mit den physischen Implementierungsdetails oder der zeitlichen Abfolge von Prozessen. Stattdessen bietet es eine Übersicht auf hoher Ebene des logischen Informationsflusses.
Wesentliche Komponenten eines DFD
- Externe Entitäten: Diese stellen Quellen oder Ziele von Daten außerhalb der Systemgrenze dar. Es könnten Benutzer, andere Systeme oder Organisationen sein. Sie initiieren oder empfangen Daten, verarbeiten sie jedoch innerhalb des Kontextes dieses spezifischen Modells nicht.
- Prozesse: Als abgerundete Rechtecke dargestellt, sind dies Aktivitäten, die Eingabedaten in Ausgabedaten umwandeln. Ein Prozess verändert den Zustand oder die Form der Informationen, die durch ihn hindurchfließen. Es ist entscheidend, dass jeder Prozess mindestens eine Eingabe und eine Ausgabe hat.
- Datenbanken: Diese sind Speicherorte, an denen Daten für spätere Verwendung gehalten werden. Im DFD stellen sie Dateien, Datenbanken oder Archive dar. Sie implizieren keine bestimmte Technologie, sondern lediglich das Vorhandensein von dauerhafter Speicherung.
- Datenflüsse: Als Pfeile dargestellt, zeigen sie die Richtung des Datenflusses. Jeder Fluss sollte mit dem Namen des übertragenen Datenpakets beschriftet sein. Datenflüsse verbinden Entitäten, Prozesse und Speicher.
Abstraktionsstufen
DFDs werden typischerweise hierarchisch erstellt, um die Komplexität zu bewältigen:
- Kontextdiagramm (Ebene 0): Dies ist die höchste Abstraktionsstufe. Es zeigt das gesamte System als einen einzigen Prozess und identifiziert alle externen Entitäten, die mit ihm interagieren. Es definiert die Grenzen des Systems eindeutig.
- Diagramm der Ebene 1: Dies zerlegt den einzelnen Prozess aus dem Kontextdiagramm in wesentliche Teilprozesse. Es liefert detailliertere Informationen darüber, wie das System Daten intern verarbeitet, ohne sich in der Logik zu verlieren.
- Ebene 2 und darüber: Diese Diagramme zerlegen spezifische Prozesse aus Ebene 1 weiter auf. Diese Stufe wird oft bei komplexen Modulen verwendet, bei denen bestimmte Datenumformungen genau definiert werden müssen.
Wann man DFD anwendet
DFDs sind am wirksamsten während der Anforderungssammlung und der funktionalen Gestaltungsphase. Sie helfen den Stakeholdern, das Verhalten des Systems zu visualisieren, ohne durch technische Einschränkungen abgelenkt zu werden. Sie sind besonders nützlich für:
- Das Aufspüren fehlender Datenanforderungen.
- Die Kommunikation von Geschäftsprozessen an nicht-technische Stakeholder.
- Die Definition des Projektumfangs.
- Die Analyse der Informationssicherheit durch Identifizierung der Stellen, an denen vertrauliche Daten eintreten und verlassen.
Verständnis des Entitäts-Beziehungs-Diagramms (ERD) 🔗
Während das DFD die Bewegung verfolgt, konzentriert sich das Entitäts-Beziehungs-Diagramm auf die Struktur. Ein ERD ist ein konzeptionelles Modell, das verwendet wird, um die Datenanforderungen und Beziehungen innerhalb einer Datenbank zu definieren. Es beschreibt die statische Natur der Daten und gewährleistet Integrität und Normalisierung.
Wichtige Bestandteile eines ERD
- Entitäten: Dargestellt als Rechtecke, handelt es sich um Gegenstände oder Konzepte aus der realen Welt, über die Daten gespeichert werden. Beispiele hierfür sind „Kunde“, „Bestellung“ oder „Produkt“. Entitäten sind die Bausteine der Datenstruktur.
- Attribute: Dies sind die Eigenschaften oder Merkmale einer Entität. Sie werden normalerweise innerhalb des Entitätsfeldes oder daran angehängt aufgelistet. Attribute definieren die spezifischen Datenelemente, wie beispielsweise „Kunden-ID“ oder „Bestelldatum“. Einige Attribute fungieren als Primärschlüssel und identifizieren eine Aufzeichnung eindeutig.
- Beziehungen: Dargestellt als Rauten oder Linien, definieren sie, wie Entitäten miteinander interagieren. Eine Beziehung zeigt an, dass eine Aufzeichnung in einer Entität mit einer Aufzeichnung in einer anderen Entität verknüpft ist.
- Kardinalität: Dies definiert die quantitative Beziehung zwischen Entitäten. Häufige Kardinalitäten sind Eins-zu-Eins (1:1), Eins-zu-Viele (1:N) und Viele-zu-Viele (M:N). Das Verständnis der Kardinalität ist entscheidend, um Datenredundanz zu vermeiden.
Normalisierung und Datenintegrität
ERDs sind oft der Ausgangspunkt für die Normalisierung. Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Integrität zu verbessern. Ein ERD hilft dabei, das logische Schema zu visualisieren, bevor physische Tabellen erstellt werden. Es stellt sicher, dass:
- Daten werden unnötigerweise nicht dupliziert.
- Die Referenzintegrität wird gewahrt (z. B. kann eine Bestellung nicht ohne einen Kunden existieren).
- Einschränkungen wie Eindeutigkeit und Pflichtfelder sind eindeutig.
Wann sollte ein ERD angewendet werden
ERDs sind während der Datenbankentwurfsphase unverzichtbar. Sie schließen die Lücke zwischen geschäftlichen Anforderungen und technischer Umsetzung. Sie sind am besten geeignet, wenn:
- Das Schema für eine relationale Datenbank entworfen wird.
- Datenbeschränkungen und Überprüfungsregeln definiert werden.
- Die Datenkonsistenz über die gesamte Anwendung hinweg gewährleistet wird.
- Die Effizienz der Datenabrufung und Strategien für Indizierung geplant werden.
Wichtige Unterschiede auf einen Blick 🆚
Der Vergleich dieser beiden Modelle nebeneinander macht ihre unterschiedlichen Zwecke deutlich. Obwohl sie in ihrer visuellen Komplexität ähnlich erscheinen können, unterscheiden sich ihre Absichten deutlich.
| Funktion |
Datenumlaufdiagramm (DFD) |
Entitäts-Beziehungs-Diagramm (ERD) |
| Hauptaugenmerk |
Prozesse und Datenfluss |
Datenstruktur und Beziehungen |
| Zeitdimension |
Dynamisch (zeigt den Fluss über die Zeit) |
Statisch (zeigt die Struktur zu einem bestimmten Zeitpunkt) |
| Wichtige Frage |
Wie bewegt sich die Daten? |
Welche Daten werden gespeichert und wie sind sie verknüpft? |
| Zielgruppe |
Business Analysten, Interessenten |
Datenbankadministratoren, Backend-Entwickler |
| Lebenszyklusphase |
Anforderungen, funktionale Gestaltung |
Datenbankgestaltung, Implementierung |
| Logik vs. Speicherung |
Fokussiert auf Logik |
Fokussiert auf Speicherung |
| Komplexität |
Kann aufgrund vieler Flüsse komplex sein |
Kann aufgrund von Beziehungen komplex sein |
Wann sollte die Datenflussmodellierung priorisiert werden 📉
Es gibt spezifische Szenarien, in denen der DFD zum primären Werkzeug für die Systemgestaltung wird. Die Wahl des DFD als ersten Schritt ist oft der richtige Weg, wenn die Geschäftslogik der komplexeste Teil des Systems ist.
- Workflow-Automatisierung: Wenn das System komplexe Genehmigungsabläufe, Zustandsänderungen oder mehrstufige Transaktionen beinhaltet, klärt der DFD die Reihenfolge der Operationen. Er hilft dabei, Engpässe im Prozess zu identifizieren.
- Externe Integrationen: Wenn ein System mit vielen externen APIs oder veralteten Systemen interagiert, hilft der DFD dabei, die Eingangs- und Ausgangspunkte der Daten zu kartieren. Er verhindert Datenverluste bei der Übergabe zwischen Systemen.
- Sicherheitsprüfungen: Sicherheitsteams verwenden DFDs oft, um nachzuvollziehen, wie sensible Daten durch die Anwendung fließen. Sie können Punkte identifizieren, an denen Verschlüsselung erforderlich ist oder wo Zugriffssteuerungen durchgesetzt werden müssen.
- Neugestaltung von Geschäftsprozessen: Bei der Optimierung bestehender Workflows dient der DFD als Basis. Sie können den „Aktuell“-Prozess mit dem „Zukünftig“-Prozess vergleichen, um Verbesserungen zu messen.
In diesen Fällen könnte die zu frühe Fokussierung auf das ERD die Logik des Systems verschleiern. Eine Datenbank kann perfekt gestaltet sein, aber wenn der Ablauffluss fehlerhaft ist, wird die Anwendung nicht den Bedürfnissen der Benutzer entsprechen.
Wann sollte die Datenstrukturmodellierung priorisiert werden 🏗️
Umgekehrt gibt es Situationen, in denen Integrität und Struktur der Daten die entscheidenden Erfolgsfaktoren sind. Das ERD hat Vorrang, wenn Datenvolumen, Beziehungen und Einschränkungen die treibenden Kräfte sind.
- Datenintensive Anwendungen: In Systemen wie Analyseplattformen oder Data-Warehouses ist die Struktur der Daten entscheidend. Ein ERD stellt sicher, dass das Schema komplexe Abfragen und Aggregationen unterstützt.
- Legacy-Migration: Beim Verschieben von Daten von einem alten System in ein neues ist das Verständnis der bestehenden Beziehungen entscheidend. Ein ERD hilft dabei, alte Tabellen neuen Strukturen zuzuordnen und sicherzustellen, dass keine Daten verloren gehen oder beschädigt werden.
- Compliance und Governance: Branchen wie Finanzen und Gesundheitswesen erfordern strenge Daten-Governance. Ein ERD dokumentiert, wo sich Daten befinden, wer sie besitzt und wie sie mit anderen Datenpunkten verknüpft sind, was bei der Compliance-Berichterstattung hilft.
- Anforderungen an hohe Leistung: Wenn das System schnelle Lese- und Schreiboperationen erfordert, leitet der ERD Strategien für Indizierung und Partitionierung. Das Verständnis der Beziehungen hilft dabei, Join-Operationen effizient zu gestalten.
Das Überspringen des ERD in diesen Szenarien kann zu einer „Spaghetti-Datenbank“ führen, bei der Tabellen überflüssig sind, Beziehungen unklar sind und die Leistung im Laufe der Zeit abnimmt.
Beide Modelle für eine robuste Architektur integrieren 🤝
Obwohl es sinnvoll ist, zwischen DFD und ERD zu unterscheiden, nutzen die erfolgreichsten Systeme oft beide. Sie ergänzen sich, sind nicht gegenseitig ausschließend. Ein robustes Systemdesign-Verfahren bewegt sich typischerweise von der Fluss- zur Strukturbeschreibung.
Der sequenzielle Ansatz
- Den Umfang mit DFD definieren: Beginnen Sie mit einem Kontextdiagramm, um die Grenzen zu verstehen. Identifizieren Sie alle Eingaben und Ausgaben.
- Prozesse zerlegen: Zerlegen Sie die Prozesse, um die spezifischen Datenumformungen zu verstehen, die erforderlich sind.
- Datenentitäten identifizieren: Während Sie die Datenflüsse analysieren, identifizieren Sie die persistierenden Objekte, die bewegt werden. Diese werden zu Kandidaten für die Entitäten im ERD.
- ERD entwerfen: Erstellen Sie das Entity-Relationship-Diagramm, um festzulegen, wie diese Entitäten gespeichert und miteinander verknüpft werden.
- Den Fluss validieren: Mappen Sie die Datenflüsse zurück zu den Datenbanktabellen. Stellen Sie sicher, dass jeder Prozess im DFD einer entsprechenden Speicheroperation im ERD entspricht.
Zuordnung von Datenlagern
In einem DFD ist ein Datenlager ein generischer Platzhalter. In einem ERD wird dasselbe Datenlager zu einer detaillierten Tabellendefinition. Der Zuordnungsprozess beinhaltet:
- Konvertierung von DFD-Datenlagern in ERD-Entitäten.
- Sicherstellen, dass alle Attribute in den DFD-Flüssen in den ERD-Attributen berücksichtigt werden.
- Überprüfen, ob die Kardinalität im ERD die Vielfachheit der Flüsse im DFD unterstützt.
Zum Beispiel muss der ERD bei einem DFD, der einen „Kunden“ zeigt, der mehrere „Bestellungen“ sendet, eine Eins-zu-Viele-Beziehung zwischen den Entitäten Kunden und Bestellungen widerspiegeln. Wenn der DFD eine komplexe Many-to-Many-Beziehung impliziert (z. B. „Studenten“ und „Kurse“), muss der ERD eine assoziative Entität einführen, um sie aufzulösen.
Häufige Fehler, die vermieden werden sollten ⚠️
Das Vermischen dieser Modelle oder ihre falsche Verwendung kann zu erheblichem technischem Schuldenberg führen. Hier sind häufige Fehler, auf die Sie achten sollten.
1. Vermischung von Logik und Speicherung
Schließen Sie keine Verarbeitungslogik in ein ERD ein. Ein ERD sollte Struktur definieren, nicht Verhalten. Wenn Sie sich dabei ertappen, Pfeile zu zeichnen, die in einem ERD „Verarbeitung“ darstellen, beschreiben Sie wahrscheinlich stattdessen ein DFD.
2. Übermodellierung des DFD
Ein DFD sollte kein Ablaufdiagramm des Codes sein. Er sollte keine Einzelheiten zu jeder bedingten Verzweigung oder Fehlerbehandlungsroutine enthalten. Halten Sie den DFD auf einer logischen Ebene. Wenn Sie jedes „if-else“-Statement detaillieren, wird die Darstellung unleserlich und verliert ihren Wert als Übersicht auf hoher Ebene.
3. Ignorieren der Kardinalität im ERD
Das Zeichnen von Linien zwischen Entitäten ohne Angabe der Kardinalität ist ein häufiger Fehler. Eine Linie allein sagt Ihnen nicht, ob ein Kunde null Bestellungen oder eine Million haben kann. Geben Sie immer 1:1, 1:N oder M:N an, um Mehrdeutigkeiten zu vermeiden.
4. Vernachlässigung von Datenattributen
Beide Diagramme leiden unter vagen Datenattributen. Im DFD sollten Flüsse beschreibend benannt werden (z. B. „Validierte Zahlungsinformationen“ statt „Daten“). Im ERD sollten Attribute Datentypen und Einschränkungen so weit wie möglich definieren.
5. Erzeugen von verwaisten Prozessen
In einem DFD kann ein Prozess nicht existieren, ohne dass Daten in ihn hinein- oder aus ihm herausfließen. Stellen Sie sicher, dass jeder Prozesskasten mindestens einen eingehenden und einen ausgehenden Fluss hat. Verwaiste Prozesse deuten auf tote Logik oder fehlende Datenanforderungen hin.
Best Practices für die Dokumentation 📝
Um Klarheit und Nutzen zu gewährleisten, halten Sie sich an diese Dokumentationsstandards.
- Konsistente Benennung:Verwenden Sie die gleiche Terminologie in beiden Diagrammen. Wenn ein DFD es als „Kunde“ bezeichnet, sollte das ERD es ebenfalls als „Kunde“ bezeichnen, nicht als „Benutzer“. Konsistenz verringert die kognitive Belastung für das Team.
- Versionskontrolle:Behandeln Sie Diagramme wie Code. Pflegen Sie eine Versionsgeschichte. Wenn sich das System weiterentwickelt, müssen die Diagramme aktualisiert werden, um den aktuellen Zustand widerzuspiegeln.
- Kontextbezogene Notizen:Fügen Sie Anmerkungen zu komplexen Bereichen hinzu. Wenn eine Beziehung unüblich ist, erklären Sie warum. Wenn ein Datenfluss einen Hintergrundjob darstellt, vermerken Sie, dass er asynchron ist.
- Überprüfungszyklen:Führen Sie formelle Überprüfungen mit Geschäftsinteressenten (für DFD) und technischen Leitern (für ERD) durch. Ein Business-Analyst könnte einen logischen Fehler im DFD erkennen, den ein Entwickler übersehen könnte, und umgekehrt.
Abschließende Gedanken zur Modellauswahl 🧠
Die Auswahl zwischen einem Datenflussdiagramm und einem Entitäts-Beziehungs-Diagramm geht nicht darum, eines gegenüber dem anderen zu bevorzugen. Es geht darum, das richtige Werkzeug für die jeweilige Phase des Design-Lebenszyklus zu wählen. Das DFD beleuchtet den Weg, den Daten nehmen, und stellt sicher, dass das System wie beabsichtigt funktioniert. Das ERD verankert diese Daten und stellt sicher, dass sie zuverlässig und effizient gespeichert werden.
Durch die Beherrschung der unterschiedlichen Zwecke dieser beiden Modelle können Architekten Systeme erstellen, die sowohl logisch konsistent als auch strukturell robust sind. Das Ziel besteht nicht darin, ein perfektes Diagramm zu erstellen, sondern ein klares Verständnis des Systems zu erzeugen. Wenn das Team in einem DFD den Prozess erkennen kann und in einem ERD die Daten, ist die Grundlage für ein erfolgreiches Projekt gelegt.
Denken Sie daran, dass diese Modelle Kommunikationswerkzeuge sind. Ihr Wert liegt in dem gemeinsamen Verständnis, das sie unter den Teammitgliedern schaffen. Unabhängig davon, ob Sie eine komplexe Transaktion abbilden oder ein Benutzerprofil definieren – bleiben Sie auf Klarheit, Genauigkeit und Ausrichtung an den Geschäftszielen fokussiert. Mit der richtigen Kombination aus Fluss und Struktur wird das Systemdesign zu einer disziplinierten Kunstform statt zu einem Ratespiel.
 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online