 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Die Systemintegration ist die Grundlage der modernen digitalen Infrastruktur. Sie verbindet unterschiedliche Anwendungen, Datenbanken und Dienste, damit sie als ein zusammenhängendes Ganzes funktionieren. Die Komplexität der Daten, die zwischen diesen Systemen fließen, kann jedoch schnell undurchsichtig werden. Hier kommt der Datenflussdiagramm (DFD) ins Spiel. Ein DFD bietet eine visuelle Darstellung, wie Daten durch ein System fließen, und hebt Eingaben, Prozesse, Speicherung und Ausgaben hervor. Bei der Systemintegration dient es als Bauplan, um die Datenherkunft und Abhängigkeiten zu verstehen.
Ohne eine klare Karte laufen Integrationsprojekte Gefahr, Dateninkonsistenzen, Sicherheitslücken und Engpässe zu erleiden. Durch die Visualisierung von Daten über mehrere Komponenten hinweg können Architekten und Ingenieure Lücken erkennen, bevor sie zu kritischen Ausfällen werden. Diese Anleitung untersucht die Methodik des Einsatzes von DFDs speziell im Kontext der Integration komplexer Systeme.
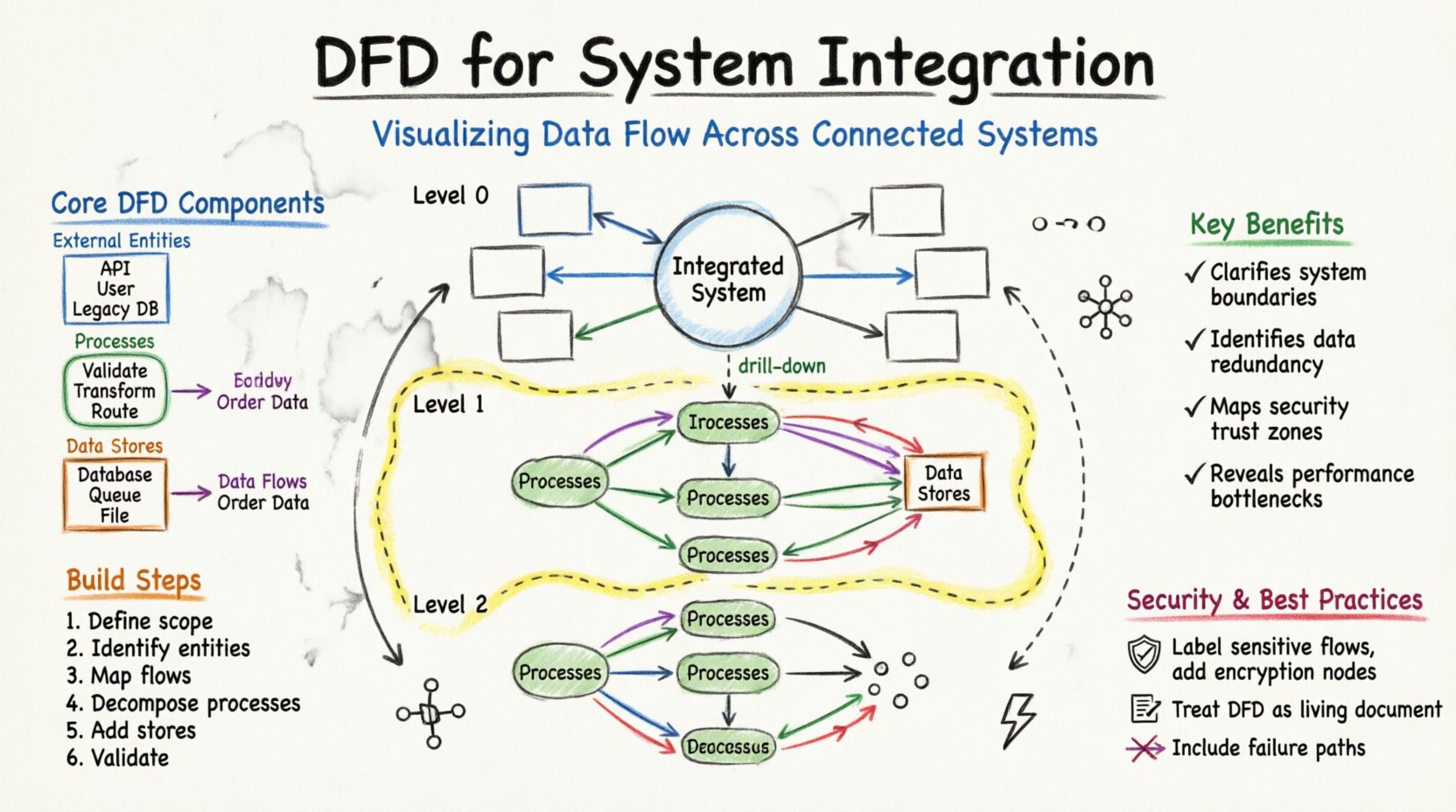
Bevor man sich mit den Spezifika der Integration beschäftigt, ist es notwendig, die grundlegenden Bausteine eines DFD zu verstehen. Diese Elemente bleiben unabhängig von der Komplexität des Systems konstant.
Es ist wichtig, DFDs von Ablaufdiagrammen zu unterscheiden. Ablaufdiagramme konzentrieren sich auf die Steuerungsflüsse und die Entscheidungslogik (if/else-Pfade). DFDs konzentrieren sich ausschließlich auf die Datenbewegung. Bei der Systemintegration ist die Datenintegrität oft wichtiger als der spezifische Entscheidungspfad. Daher ist ein DFD das bevorzugte Werkzeug zur Abbildung von Datenumwandlungs-Pipelines.
Wenn mehrere Systeme miteinander kommunizieren müssen, ähnelt die Architektur oft einem Netzwerk. Ohne eine zentrale Visualisierung können die Verbindungen zu einem verwirrenden Gewirr werden. Ein DFD hilft, diese Komplexität zu klären, indem die Informationen schichtweise dargestellt werden.
Um die Komplexität zu bewältigen, werden DFDs typischerweise auf verschiedenen Abstraktionsstufen erstellt. Diese Hierarchie ermöglicht es den Beteiligten, das System von einer übergeordneten Übersicht bis hin zu spezifischen technischen Details zu betrachten.
Das Kontextdiagramm ist die höchste Abstraktionsstufe. Es behandelt das gesamte integrierte System als einen einzigen Prozess. Es zeigt die Interaktion des Systems mit externen Entitäten.
Dieses Diagramm teilt den Hauptprozess in wesentliche Teilprozesse auf. Es ist die primäre Karte für Integrationsarchitekten.
Ebene-2-Diagramme gehen auf spezifische Teilprozesse aus Ebene 1 ein. Sie werden von Entwicklern und Ingenieuren verwendet, die bestimmte Logik implementieren.
Die Erstellung eines robusten DFD erfordert einen strukturierten Ansatz. Es ist nicht lediglich eine Zeichenaufgabe, sondern eine Modellierungsaktivität, die ein Verständnis der Geschäftslogik erfordert.
Beginnen Sie damit, alle Systeme aufzulisten, die an der Integration teilnehmen werden. Unterscheiden Sie zwischen Systemen, die Daten erzeugen, und solchen, die sie verbrauchen. Definieren Sie die organisatorische Grenze. Welche Datenströme sind intern, und welche überschreiten die Grenze in den öffentlichen Bereich?
Listen Sie jede Quelle und jedes Ziel auf. Dazu gehören:
Zeichnen Sie Pfeile, die Entitäten mit dem zentralen System verbinden. Kennzeichnen Sie diese Flüsse mit der Art der übertragenen Daten (z. B. „Bestelldetails“, „Lagerstatus“). Machen Sie sich noch keine Gedanken über die interne Logik. Konzentrieren Sie sich auf die Bewegung.
Teilen Sie das zentrale System in logische Prozesse auf. Zum Beispiel, anstatt einen Prozess namens „Bestellung bearbeiten“ zu haben, teilen Sie ihn in „Bestellung überprüfen“, „Lagerbestand prüfen“ und „Zahlung verarbeiten“ auf. Diese Zerlegung zeigt auf, wo Daten transformiert werden.
Identifizieren Sie, wo Daten gespeichert werden müssen. Bei der Integration könnte dies ein temporärer Staging-Bereich oder ein dauerhafter Datenspeicher sein. Stellen Sie sicher, dass jeder Datenbestand mit einem Prozess verbunden ist, der darauf schreibt, und einem Prozess, der davon liest.
Prüfen Sie auf häufige Fehler. Stellen Sie sicher, dass kein Datenfluss von nichts beginnt oder endet. Jeder Pfeil muss einen Anfang und ein Ende haben. Überprüfen Sie, dass Datenbestände nicht umgangen werden, wenn Daten persistieren müssen.
Die Erstellung von DFDs für die Integration ist nicht ohne Hürden. Dateninkonsistenzen und versteckte Abhängigkeiten sind häufige Fallstricke. Die folgende Tabelle zeigt häufige Probleme und empfohlene Ansätze zur Lösung dieser Probleme auf.
| Herausforderung | Beschreibung | Lösung |
|---|---|---|
| Datenredundanz | Mehrere Systeme speichern die gleichen Kundendaten unabhängig voneinander. | Konsolidieren Sie die Datenbestände im DFD, wenn möglich, zu einer einzigen Quelle der Wahrheit. |
| Versteckte Abhängigkeiten | Datenflüsse hängen von Hintergrundaufgaben ab, die im Diagramm nicht sichtbar sind. | Schließen Sie asynchrone Prozesse und Hintergrundjobs als explizite Prozesse im DFD ein. |
| Sicherheitslücken | Unverschlüsselte Daten fließen über öffentliche Netzwerke. | Kennzeichnen Sie sichere Flüsse und wenden Sie Verschlüsselungsprozesse an den Netzwerkrändern an. |
| Schnittstellen von veralteten Systemen | Alte Systeme verfügen nicht über standardisierte APIs. | Modellieren Sie die erforderlichen Wrapper oder Middleware, um Datenformate zu übersetzen. |
| Volumen-Spitzen | Der Datenfluss steigt unerwartet während Spitzenzeiten an. | Fügen Sie Puffer-Datenbestände hinzu, um Verkehrs-Spitzen vor der Verarbeitung abzufangen. |
Um sicherzustellen, dass das DFD im Laufe der Zeit nützlich bleibt, halten Sie sich an diese Gestaltungsprinzipien. Ein Diagramm, das zu komplex ist, wird unlesbar; eines, das zu einfach ist, wird ungenau.
Bei der Systemintegration bewegt sich Daten selten genau so, wie sie sind. Formate ändern sich, Felder werden hinzugefügt und Werte berechnet. Das DFD muss diese Umformungen widerspiegeln.
Wenn Daten in ein System eintreten, müssen sie oft standardisiert werden. Beispielsweise könnte das Datumsformat in einem System „TT/MM/JJJJ“ und in einem anderen „JJJJ-MM-TT“ sein. Das DFD sollte einen Prozessknoten speziell für „Formatstandardisierung“ anzeigen.
Manchmal werden Daten mit anderen Quellen kombiniert, um ihnen mehr Wert zu verleihen. Beispielsweise könnte eine Bestellung mit aktuellen Wechselkursen bereichert werden. Dazu ist ein Prozess erforderlich, der Daten aus einer sekundären Quelle (wie einem Währungsspeicher) abruft und sie mit dem Hauptfluss verbindet.
Sicherheitsanforderungen verlangen oft, dass sensible Daten versteckt werden. Wenn ein Prozess Daten an ein Protokollsystem sendet, sollte das DFD einen Transformations-Schritt anzeigen, der Kreditkartennummern oder Sozialversicherungsnummern maskiert, bevor die Daten die sichere Zone verlassen.
Verschiedene architektonische Muster nutzen Datenflüsse unterschiedlich. Das Verständnis dieser Muster hilft dabei, das richtige DFD zu zeichnen.
Ein DFD ist kein einmaliger Artefakt. Systeme entwickeln sich weiter, neue APIs werden eingeführt und alte werden abgeschaltet. Ein veraltetes Diagramm kann zu Fehlern und Sicherheitslücken führen. Die Wartung ist eine entscheidende Phase im Lebenszyklus des DFDs.
Aktualisierungen des DFD sollten ausgelöst werden durch:
Halten Sie das Diagramm mit dem Code-Repository oder den Konfigurationsdateien verknüpft. Wenn ein Entwickler ein Skript zur Datenzuordnung ändert, sollte er das DFD gleichzeitig aktualisieren. Dadurch bleibt die Dokumentation eine verlässliche Quelle der Wahrheit.
Sicherheit ist kein Zusatz; sie ist ein grundlegender Aspekt des Datenflusses. Bei der Visualisierung von Daten müssen Sie berücksichtigen, wo Vertrauensgrenzen bestehen.
Um die praktische Anwendung zu veranschaulichen, betrachten Sie einen Fall, bei dem ein Unternehmen Produkte über eine Website, eine Mobile-App und ein physisches Geschäft verkauft.
Die Entitäten umfassen die Website, die Mobile-App, das POS-System und den Kunden.
Wichtige Prozesse umfassen „Bestellannahme“, „Bestandsabzug“ und „Zahlungsabwicklung“.
Wenn ein Kunde ein Produkt kauft:
Diese Visualisierung macht deutlich, dass, wenn der Bestandsbestand ausgefallen ist, die Bestellannahme möglicherweise gelingt, die Erfüllung jedoch fehlschlägt. Diese Abhängigkeit ist nur über das Diagramm sichtbar.
Datenumlaufdiagramme bieten eine strukturierte Möglichkeit, die Bewegung von Informationen innerhalb komplexer Systemintegrationen zu verstehen. Sie wandeln abstrakten Code und API-Aufrufe in eine visuelle Sprache um, die Stakeholder verstehen können. Indem man die hier aufgeführten Schritte befolgt, können Teams genaue Karten ihrer Datenarchitektur erstellen.
Effektive DFDs führen zu einer besseren Systemgestaltung, weniger Integrationsfehlern und klareren Sicherheitsgrenzen. Sie dienen als lebendiges Dokument, das die Entwicklung und Wartung leitet. In einer Umgebung, in der Daten das wertvollste Gut sind, ist die Visualisierung ihrer Reise keine Option – sie ist eine Notwendigkeit für betriebliche Exzellenz.