 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











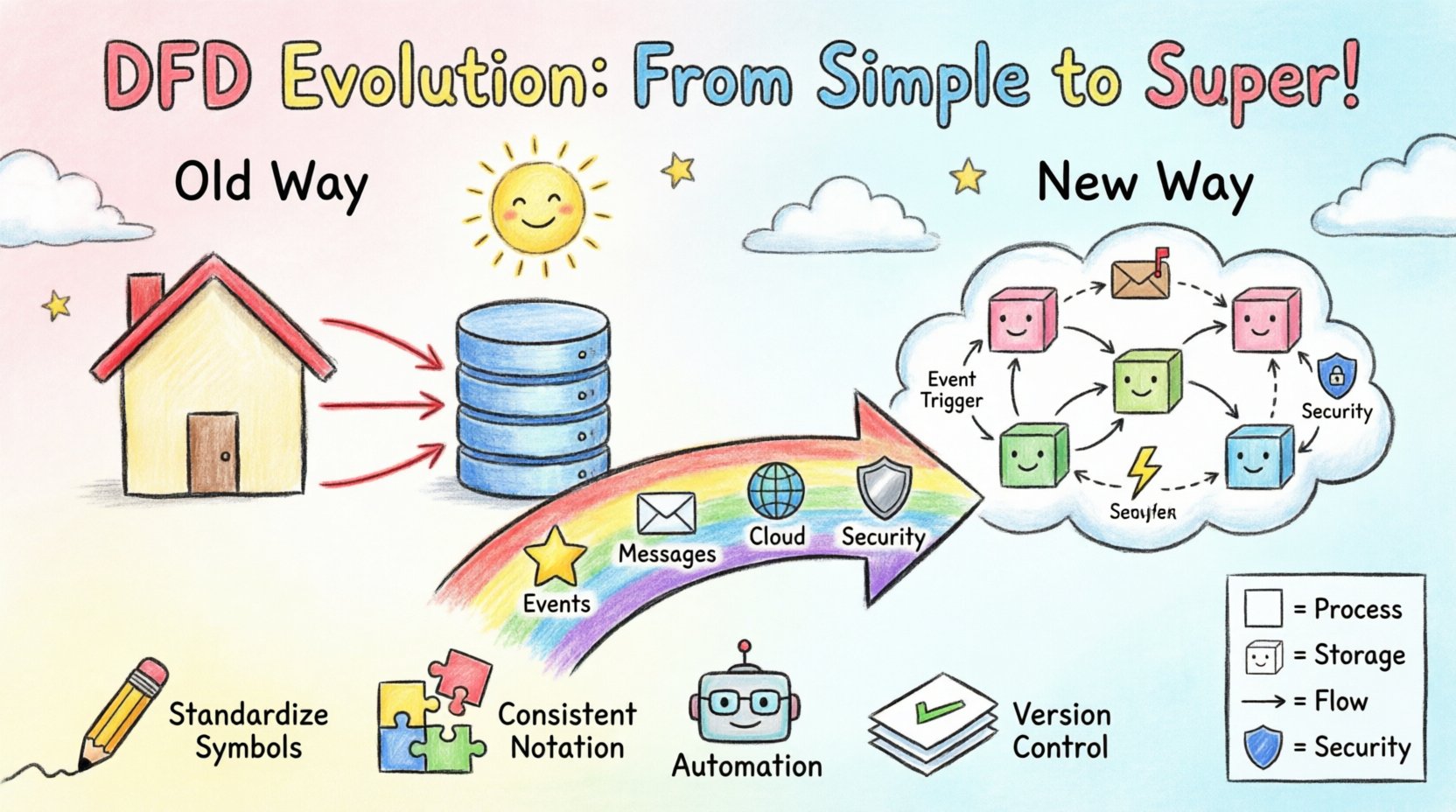
Die Systemanalyse stützt sich seit langem auf visuelle Darstellungen, um komplexe Logik zu vermitteln. Das Datenflussdiagramm (DFD) bleibt ein Eckpfeiler dieser Praxis. Doch die Landschaft der Softwarearchitektur hat sich dramatisch verändert. Wir sind von monolithischen Anwendungen zu verteilten Microservices übergegangen, von lokalen Datenbanken zu cloudbasierten Speicherlösungen und von synchronen Anfragen zu asynchronen Ereignisströmen. Das traditionelle DFD, das für einfachere, lineare Prozesse konzipiert wurde, steht vor neuen Herausforderungen in diesen Umgebungen. Dieser Leitfaden untersucht, wie die Methode sich weiterentwickelt, um weiterhin relevant zu bleiben und eine genaue Modellierung zu gewährleisten, ohne obsolet zu werden. 🛠️
Bevor wir die Entwicklung untersuchen, ist es notwendig, die Grundlage zu schaffen. Ein Standard-DFD visualisiert den Fluss von Informationen durch ein System. Er konzentriert sich auf was das System tut, nicht auf wie es das tut. Diese Unterscheidung trennt die Prozessmodellierung von der strukturellen Gestaltung. Die zentralen Komponenten bleiben über Generationen hinweg konstant:
Im traditionellen Kontext waren diese Diagramme hierarchisch aufgebaut. Ein Kontextdiagramm bot eine Übersichtsebene (Stufe 0), die dann in detaillierte Diagramme der Stufe 1 und Stufe 2 zerlegt wurde. Das funktionierte gut, als ein System einen klaren Anfang und ein eindeutiges Ende hatte und Daten vorhersehbar von der Eingabe zur Ausgabe flossen. Moderne Systeme verfügen jedoch oft nicht über einen einzigen Einstiegspunkt oder ein eindeutiges Ende. Daten fließen kontinuierlich ein und aus, oft in Echtzeit. 🔄
Der Übergang von Monolithen zu verteilten Systemen erzeugt Reibung bei der statischen Modellierung. In einer monolithischen Anwendung könnte eine Datenbanktransaktion eine Reihe von Funktionsaufrufen auslösen, die sofort abgeschlossen werden. Ein DFD könnte eine gerade Linie von der Datenbank zum Prozess zur Ausgabe zeichnen. In einer Microservice-Umgebung ist die Situation viel komplexer.
Moderne Systeme stützen sich häufig auf Nachrichtenbroker und Warteschlangen. Eine Anfrage wird empfangen, in einer Warteschlange gespeichert und später von einem Worker verarbeitet. Traditionelle DFDs haben Schwierigkeiten, Zeit zu repräsentieren. Sie implizieren einen sofortigen Fluss. Ein statischer Pfeil vermittelt nicht leicht, dass Datenstunden in einem Puffer verbleiben können, bevor der nächste Prozess aktiv wird. Dies führt zu Unklarheiten bei der Analyse des Systemverhaltens.
Cloud-Architekturen nutzen häufig zustandslose Container, die hoch- und heruntergefahren werden. Ein DFD impliziert normalerweise einen dauerhaften Prozess. Wenn ein Prozess flüchtig ist, muss das Diagramm klären, wo der Zustand gespeichert wird (die Datenbank) im Gegensatz zu dem Ort, an dem die Logik liegt (die Rechenressource). Wenn das Diagramm diese Unterscheidung nicht trifft, können Entwickler fälschlicherweise annehmen, dass der Zustand innerhalb des Prozesses selbst erhalten bleibt, was zu Fehlern führt.
Ältere Modelle behandelten Datenbanken oft als generische Kästen. Moderne Compliance erfordert das Verständnis, wo Daten geografisch gespeichert sind und wie sie verschlüsselt werden. Ein DFD muss nun die Datenhoheit und Sicherheitsstufen angeben. Wenn ein Datenfluss eine Sicherheitszone überschreitet, sollte das Diagramm diese Grenze widerspiegeln, nicht nur die logische Verbindung.
Um diese Lücken zu schließen, passen Fachleute die Standardnotation an, um ereignisgesteuerte Architekturen (EDA) zu berücksichtigen. Die zentrale Idee bleibt der Datenfluss, doch die Auslöser ändern sich.
Diese Anpassung erfordert eine Veränderung der Perspektive. Das Diagramm ist nicht länger nur eine Karte des Systems; es ist eine Karte der Vorfälle die das System antreiben. Es hilft den Beteiligten, den Lebenszyklus eines Datensatzes von der Erstellung bis zur endgültigen Nutzung zu verstehen, einschließlich der Pausen dazwischen. 🕒
Wenn Anwendungen in die Cloud verlegt werden, muss das DFD mit API-Verträgen und Dienstgrenzen übereinstimmen. Das Diagramm dient als Brücke zwischen geschäftlichen Anforderungen und technischer Umsetzung.
Die meisten modernen Systeme stellen einen API-Gateway bereit. In einem DFD ersetzt dieser den generischen „externen Entität“. Der Gateway wird zu einem spezifischen Prozess, der für Routing, Authentifizierung und Rate Limiting verantwortlich ist. Das Diagramm sollte die Umwandlung der eingehenden Anfrage in einen internen Befehl zeigen. Dies klärt die Trennung der Verantwortlichkeiten.
In verteilten Datenbanken wird Daten oft in Shards aufgeteilt. Ein traditionelles Datenbanksymbol reicht nicht aus. Das Diagramm sollte anzeigen, dass ein Prozess möglicherweise mehrere Shards abfragen kann, um eine Antwort zusammenzustellen. Dies veranschaulicht die Komplexität von Leseoperationen gegenüber Schreiboperationen. Zum Beispiel könnte eine Schreiboperation zu einer einzigen Partition gehen, während eine Leseoperation aus drei aggregiert wird.
Dienste kennen oft zu Entwurfszeit die Netzwerkadresse anderer Dienste nicht. Sie entdecken sie zur Laufzeit. Ein DFD kann dies durch Verwendung eines „Diensteregisters“ darstellen. Prozesse verbinden sich mit dem Register, um den aktuellen Endpunkt eines abhängigen Dienstes zu finden. Dies fügt der logischen Strömung eine Ebene der Infrastrukturtransparenz hinzu.
Das Verständnis der Unterschiede hilft Teams, die richtige Abstraktionsstufe zu wählen. Die folgende Tabelle zeigt die wesentlichen Unterschiede in der heutigen und früheren Konstruktion und Interpretation von DFDs auf.
| Funktion | Traditionelles DFD | Modernes DFD |
|---|---|---|
| Flussrichtung | Synchron, sofort | Asynchron, verzögert oder in Batches |
| Art des Prozesses | Monolithisch, langlaufend | Mikroservice, kurzlebig, zustandslos |
| Speicherung | Zentralisierte Datenbank | Gesplittert, verteilt oder Objektspeicherung |
| Auslöser | Eintreffen von Eingabedaten | Ereignisse, Nachrichten oder geplante Aufgaben |
| Grenzen | Systemgrenze | Sicherheitszonen und API-Gateways |
| Konkurrenz | Häufig ignoriert | Explizit modelliert (Warteschlangen, Sperren) |
Je komplexer die Diagramme werden, desto größer wird das Risiko der Lesbarkeit. Die folgenden Praktiken stellen sicher, dass das DFD ein nützliches Werkzeug bleibt und kein verwirrendes Artefakt.
Sicherheit ist kein nachträglicher Gedanke mehr. Sie muss bereits in der Entwurfsphase verankert sein. Ein DFD ist ein hervorragendes Werkzeug, um Sicherheitsrisiken zu identifizieren, indem gezeigt wird, wo Daten preisgegeben werden.
Jedes Mal, wenn Daten von einem Prozess zum anderen übergehen, wird eine Vertrauensgrenze überschritten. In einem modernen System könnte dies von einer öffentlichen API zu einem internen Mikrodienst sein. Das DFD sollte diese Grenzen hervorheben. Wenn ein Datenfluss eine Grenze ohne Verschlüsselung oder Authentifizierung überschreitet, zeigt das Diagramm sofort eine Schwachstelle auf.
Nicht alle Datenflüsse haben die gleiche Bedeutung. Sensible Informationen wie PII (personenbezogene Daten) erfordern strengere Behandlung. Das Diagramm kann Farbcodierung oder spezifische Symbole verwenden, um sensible Flüsse zu kennzeichnen. Dadurch wird sichergestellt, dass Entwickler bei der Implementierung der Logik die Verschlüsselung und Zugriffssteuerung für diese spezifischen Pfade priorisieren.
Vorschriften wie die DSGVO oder HIPAA legen fest, wie Daten gespeichert und bewegt werden müssen. Ein modernes DFD kann Datenflüsse den Compliance-Anforderungen zuordnen. Zum Beispiel könnte ein Datenbestand als „Nur EU-Region“ gekennzeichnet sein. Wenn ein Prozess Daten aus diesem Bestand in eine andere Region zieht, markiert das Diagramm eine mögliche Verletzung der Compliance. Dies ermöglicht es Architekten, Probleme zu beheben, bevor Code geschrieben wird.
Eine der größten Herausforderungen bei DFDs ist die Wartung. Wenn sich der Code ändert, wird das Diagramm oft veraltet. Moderne Arbeitsabläufe zielen darauf ab, diese Lücke durch Automatisierung zu schließen.
Während vollständig automatisierte Diagramme noch nicht perfekt sind, bieten sie eine Grundlage, die viel näher an der Realität liegt als ein statisches Dokument, das vor Monaten erstellt wurde. Dadurch bleibt die Dokumentation aktuell, während das System iteriert. 🔄
Die Entwicklung von DFDs ist weiterhin im Gange. Mit dem Fortschritt der Technologie entwickeln sich auch die Modellierungstechniken.
Maschinelles Lernen führt zu nicht-deterministischen Flüssen ein. Ein Prozess könnte je nach Wahrscheinlichkeit unterschiedliche Ergebnisse liefern, anstatt auf festen Logikregeln basieren. Zukünftige DFDs könnten möglicherweise Konfidenzintervalle oder Trainingsdatenflüsse getrennt von Inferenzdatenflüssen darstellen. Dies fügt einer neuen Dimension für Datenspeicher- und Prozessknoten hinzu.
Statische Diagramme sind gut für die Gestaltung, aber was ist mit dem Betrieb? Zukünftige Versionen könnten Diagramme mit Live-Dashboards verknüpfen. Wenn ein Datenfluss in der Produktion blockiert ist, könnte der entsprechende Pfeil im Diagramm rot aufleuchten. Dadurch entsteht ein lebendiges Dokument, das den aktuellen Zustand des Systems widerspiegelt.
Derzeit gibt es kein universelles Standard für die Darstellung von Ereignissen in DFDs. Sobald die Branche sich auf bestimmte Ereignismuster (wie CQRS oder Event Sourcing) konzentriert, wird vermutlich ein standardisierter Satz an Symbolen entstehen. Dadurch werden Diagramme zwischen verschiedenen Teams und Organisationen interoperabel.
Um Ihre aktuellen Modellierungspraktiken anzupassen, folgen Sie dieser allgemeinen Reihenfolge.
Das Datenflussdiagramm hat Jahrzehnte technologischer Veränderungen überstanden, weil sein zentrales Ziel weiterhin gültig ist: Klarheit. Während die Notation sich anpassen muss, um Mikroservices, Cloud-Infrastruktur und asynchrone Ereignisse zu berücksichtigen, bleibt das grundlegende Ziel, den Datenfluss visuell darzustellen, unverändert. Durch die Aktualisierung der Symbole und des dahinterliegenden mentalen Modells können Teams DFDs weiterhin als primäres Werkzeug zur Systemanalyse nutzen. Die Entwicklung geht nicht darum, die Methode zu ersetzen, sondern sie zu verfeinern, um der Komplexität der modernen digitalen Landschaft gerecht zu werden. 🌐