 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











As enterprise systems grow in complexity, the models used to describe them must evolve to maintain clarity and utility. SysML (Systems Modeling Language) offers a robust foundation for system architecture and requirements engineering. However, applying these models to large-scale enterprises introduces significant challenges. Performance degradation, cognitive overload, and traceability fragmentation are common hurdles. This guide outlines structural strategies designed to manage SysML model growth effectively without compromising integrity or speed.
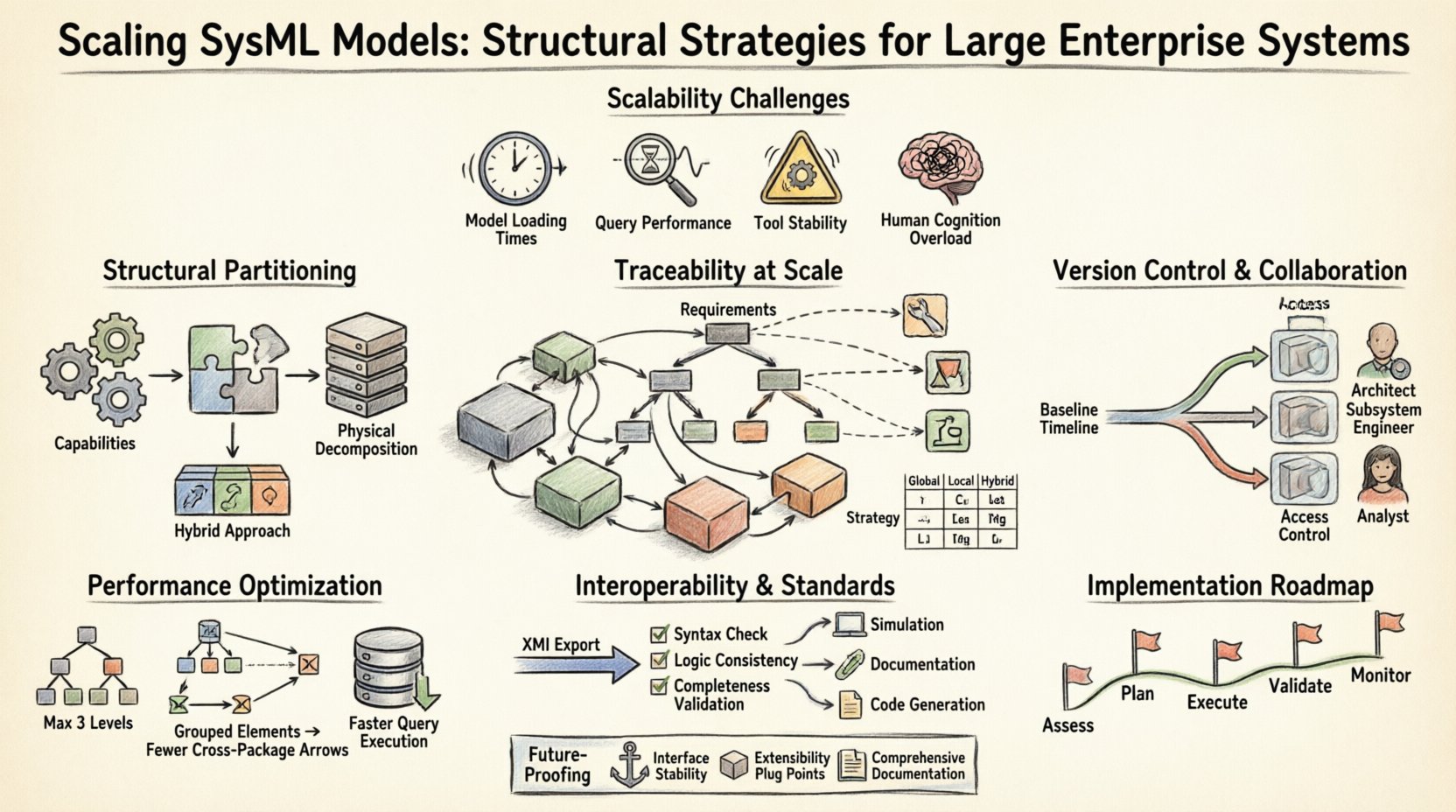
Scaling a SysML model is not merely about adding more elements; it is about maintaining the logical relationships between them. When a model reaches a certain size, typically involving thousands of blocks and requirements, standard modeling practices often fail. The primary issues include:
Addressing these issues requires a proactive approach to model organization from the outset. It is not enough to rely on the tooling to handle the load. Structural discipline is required to ensure the model remains a viable asset throughout the system lifecycle.
The most effective way to manage growth is through partitioning. This involves breaking the monolithic model into manageable units that can be developed, reviewed, and maintained independently. There are several approaches to structuring these partitions.
Decisions on how to partition the model often depend on the engineering methodology. Some teams prefer functional decomposition, organizing by capability. Others prefer physical decomposition, organizing by subsystem or hardware component.
A hybrid approach often yields the best results. The top-level package represents the system, while sub-packages represent major subsystems. Within those, functional packages handle behavior, and physical packages handle allocation.
Reference models allow teams to reuse common structures without duplicating content. This is critical for enterprises managing multiple similar products. Instead of recreating a standard power distribution block for every new system, a reference block is defined once and instantiated where needed.
This reduces model size and ensures consistency. When a change is made to the reference, all instantiations can be updated. However, care must be taken to prevent circular dependencies and ensure that the reference model remains generic enough to apply across different contexts.
Traceability is the backbone of systems engineering. In a large enterprise, the number of requirements can reach into the tens of thousands. Maintaining links between requirements, design blocks, and verification activities becomes a significant logistical task.
Requirements should be structured hierarchically. Top-level system requirements are refined into lower-level subsystem and component requirements. This structure allows for targeted views. Engineers can focus on the requirements relevant to their specific subsystem without being overwhelmed by the entire system scope.
Generating a full traceability matrix for a massive model can be resource-intensive. It is better to generate matrices for specific subsystems or phases of development. This reduces processing time and provides more relevant information to the stakeholders involved.
| Strategy | Benefit | Complexity |
|---|---|---|
| Global Traceability | End-to-End visibility | High |
| Local Traceability | Faster queries, focused views | Low |
| Hybrid Traceability | Balanced visibility and performance | Medium |
When multiple teams work on the same model, version control becomes essential. Standard file-based versioning often fails with SysML models because the internal structure is not easily diffable. Changes to links or constraints can cause merge conflicts that are difficult to resolve.
Baselines represent a snapshot of the model at a specific point in time. They are crucial for defining the scope of a release. By creating baselines for each subsystem, teams can lock specific versions of the architecture while others evolve.
For enterprise environments, a central repository is often necessary. This allows for concurrent access without direct file locking. Teams can work on their assigned packages and synchronize changes periodically. This reduces the risk of data loss and ensures that the master model remains consistent.
Scalability is not just technical; it is also organizational. The way teams interact with the model dictates its success. Clear roles and responsibilities must be established to prevent conflicting changes.
Not every engineer needs access to every part of the model. Access control should be enforced based on the subsystem or domain. This limits the surface area for errors and reduces the cognitive load on the user.
Systems do not exist in a vacuum. Integration with other tools is necessary for simulation, code generation, or documentation. Establishing clear integration points early prevents data silos. Data should flow from the model to downstream tools without manual re-entry.
| Integration Type | Use Case | Consideration |
|---|---|---|
| Requirements Management | External requirement tools | Link stability |
| Simulation | Model execution | Parameter consistency |
| Documentation | PDF or Web reports | Template maintenance |
| Code Generation | Embedded software | Mapping accuracy |
Even with good structure, performance issues can arise. Understanding the internal mechanics of the modeling environment helps in tuning the model for speed.
While inheritance promotes reuse, deep hierarchies can slow down resolution. If a block inherits from a parent, which inherits from another, the tool must traverse the chain every time the block is accessed. Keep inheritance chains shallow, ideally no deeper than three levels.
Links between elements in different packages require additional lookup time. While necessary for traceability, excessive cross-references can fragment the model. Group related elements together. If a link is required across packages, ensure the packages are logically related to minimize navigation overhead.
Some modeling environments provide options to optimize how data is stored. Enabling indexing for frequently queried fields, such as requirements IDs, can speed up search operations. Caching frequently accessed views can reduce load times for recurring tasks.
Enterprise systems often span multiple organizations. Ensuring that models can be exchanged is a key part of scalability. Adhering to standard exchange formats ensures that the model data survives transfer.
XML Metadata Interchange (XMI) is a standard format for exchanging model data. Using XMI allows for backup, archiving, and migration between different environments. However, XMI files can be large. Compressing these files or splitting them by subsystem is recommended for large datasets.
Automated consistency checks help maintain model health. These checks can verify that all requirements have allocated blocks, or that all interfaces are defined. Running these checks regularly prevents technical debt from accumulating.
Avoiding pitfalls is as important as implementing best practices. The following table summarizes common issues and their remedies.
| Bottleneck | Impact | Remedy |
|---|---|---|
| Unstructured Packages | Difficulty navigating | Enforce naming conventions and hierarchy |
| Redundant Elements | Increased file size | Use Reference Blocks and Value Types |
| Unlinked Requirements | Loss of traceability | Automated completeness checks |
| Complex Diagrams | Slow rendering | Use simplified views and hide unused elements |
Enterprise systems evolve over years. The modeling strategy must accommodate future growth. This means designing the structure to allow for new subsystems without breaking existing links.
Adopting these strategies requires a phased approach. It is rarely feasible to restructure a massive model overnight. Start by identifying the most problematic areas, such as slow loading times or broken traceability.
By following these structural strategies, enterprise teams can maintain a SysML model that serves as a reliable source of truth. The goal is not just to build a model, but to build a system that can be understood, managed, and evolved over its entire lifecycle.