 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Các dự án phần mềm thường vấp ngã không phải do chất lượng mã nguồn, mà do các yêu cầu bị hiểu nhầm. Khi các đội ngũ nhảy thẳng vào thiết kế hoặc phát triển mà không có bản đồ rõ ràng về luồng dữ liệu, kết quả là nợ kỹ thuật và mở rộng phạm vi. Đây chính là lúc sơ đồ luồng dữ liệu, hay DFD, thể hiện giá trị của nó. Nó đóng vai trò như một ngôn ngữ trực quan, giúp nối liền khoảng cách giữa các bên liên quan kinh doanh và các kiến trúc sư kỹ thuật.
Sơ đồ luồng dữ liệu là một biểu diễn đồ họa về luồng dữ liệu qua một hệ thống thông tin. Khác với sơ đồ lưu đồ, vốn tập trung vào logic điều khiển và các điểm ra quyết định, DFD tập trung vào luồng thông tin. Chúng cho thấy dữ liệu vào hệ thống như thế nào, được biến đổi ra sao, được lưu trữ ở đâu và rời khỏi hệ thống ra sao. Trong bối cảnh thu thập yêu cầu, sự phân biệt này là rất quan trọng. Nó chuyển cuộc trò chuyện từ hệ thống làm gìsangdữ liệu hệ thống xử lý.
Hướng dẫn này khám phá về cơ chế, lợi ích và ứng dụng chiến lược của DFD. Chúng ta sẽ xem xét cách chúng làm rõ sự mơ hồ, hỗ trợ xác thực và đảm bảo sản phẩm cuối cùng phù hợp với nhu cầu kinh doanh.
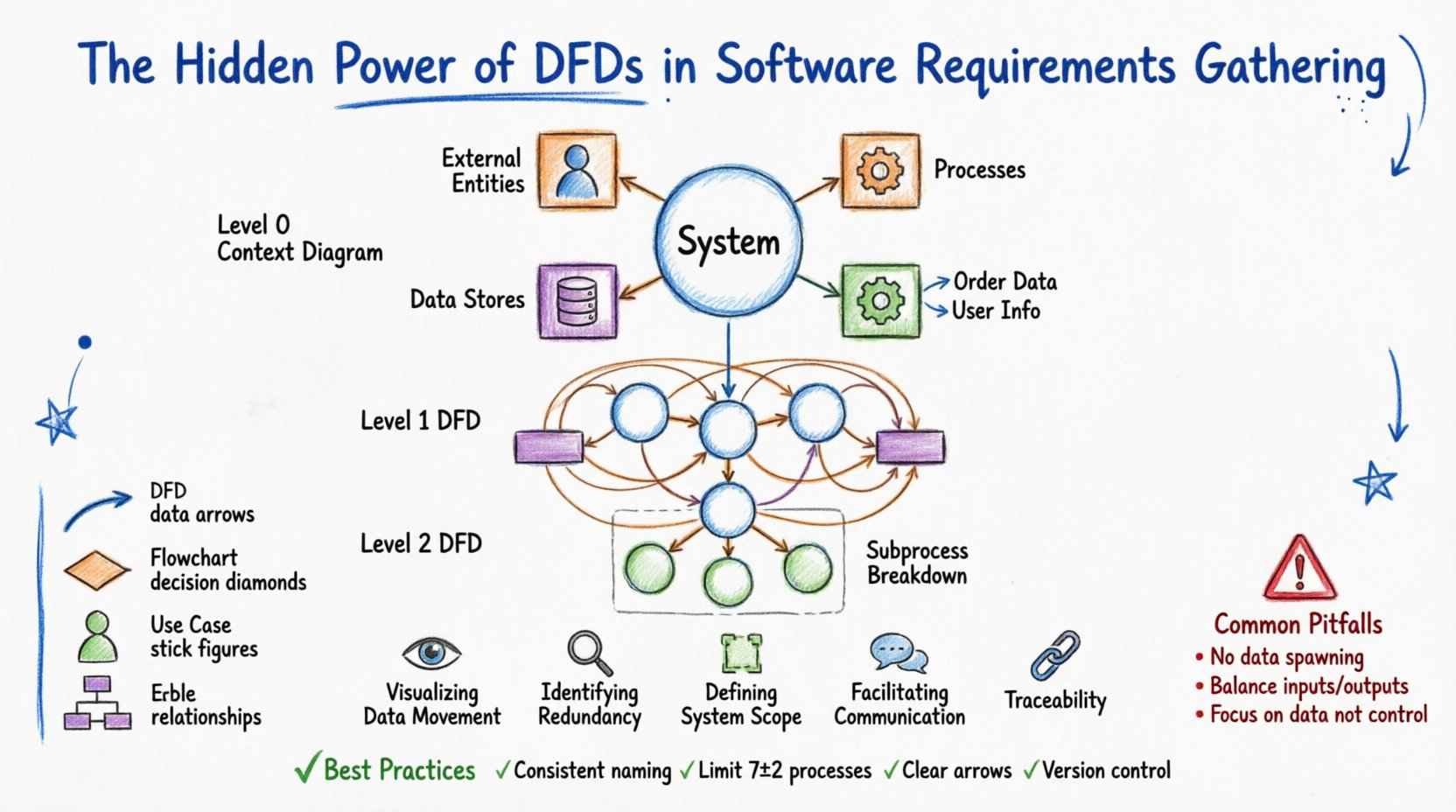
Trước khi áp dụng DFD vào các dự án phức tạp, cần phải hiểu rõ các khối xây dựng cơ bản. Một DFD gồm bốn thành phần nền tảng. Mỗi thành phần có biểu diễn hình học cụ thể và định nghĩa nghiêm ngặt về chức năng của nó trong hệ thống.
Hiểu rõ các thành phần này giúp tránh nhầm lẫn trong các buổi làm việc thu thập yêu cầu. Các bên liên quan thường nhầm lẫn giữa một quá trình và một kho dữ liệu. Một sơ đồ rõ ràng sẽ làm rõ rằng “Khách hàng” là một thực thể, nhưng “Dữ liệu khách hàng” là một kho. Sự phân biệt này là nền tảng cho việc mô hình hóa hệ thống chính xác.
Các tài liệu yêu cầu thường bị ảnh hưởng bởi những mô tả quá nhiều văn bản, dễ gây hiểu lầm. Một DFD cung cấp một nguồn thông tin duy nhất, trực quan và mang tính không gian. Dưới đây là lý do tại sao chúng không thể thiếu trong giai đoạn phân tích.
Các sơ đồ DFD không được tạo ra trong một cái nhìn duy nhất. Chúng được phân rã theo thứ tự phân cấp để quản lý độ phức tạp. Cách tiếp cận này cho phép các nhà phân tích bắt đầu bằng cái nhìn tổng quan cấp cao và đi sâu vào các chi tiết cụ thể mà không làm cho người đọc cảm thấy quá tải.
Đây là mức cao nhất. Nó biểu diễn toàn bộ hệ thống như một quá trình duy nhất. Nó thể hiện mối quan hệ của hệ thống với thế giới bên ngoài. Bạn sẽ thấy quá trình duy nhất ở trung tâm, được bao quanh bởi tất cả các thực thể bên ngoài kết nối với nhau bằng các luồng dữ liệu. Sơ đồ này trả lời câu hỏi: “Hệ thống là gì, và nó tương tác với ai?”
Ở đây, quá trình duy nhất từ sơ đồ bối cảnh được tách ra thành các quá trình con chính. Mức này thường bao gồm từ 5 đến 9 quá trình. Nó thể hiện các khu vực chức năng chính của hệ thống. Nó bao gồm các kho dữ liệu và các thực thể bên ngoài, nhưng trọng tâm là các phép biến đổi chính.
Mỗi quá trình từ mức 1 có thể được phân rã thêm thành sơ đồ mức 2. Điều này hữu ích cho các logic phức tạp. Ví dụ, quá trình “Xử lý thanh toán” có thể được chia nhỏ thành “Xác thực thẻ”, “Nạp tài khoản” và “Cập nhật sổ cái”. Việc phân rã sẽ dừng lại khi các quá trình trở nên đơn giản đủ để triển khai như một module hoặc hàm duy nhất.
Xây dựng một sơ đồ DFD hiệu quả đòi hỏi sự kỷ luật. Đó không chỉ đơn thuần là vẽ các đường thẳng; mà là việc ghi lại logic một cách chính xác. Hãy tuân theo cách tiếp cận có cấu trúc này để đảm bảo chất lượng.
Ngay cả các nhà phân tích có kinh nghiệm cũng mắc sai lầm. Nhận diện những lỗi này sớm sẽ tiết kiệm rất nhiều thời gian trong giai đoạn phát triển. Dưới đây là những vấn đề phổ biến nhất gặp phải khi mô hình hóa yêu cầu.
| Sai lầm | Mô tả | Sửa chữa |
|---|---|---|
| Sinh dữ liệu | Dữ liệu xuất hiện một cách vô cớ mà không có nguồn đầu vào. | Mỗi mũi tên phải bắt nguồn từ một thực thể, quá trình hoặc kho chứa. |
| Phá hủy dữ liệu | Dữ liệu chảy vào một quá trình nhưng biến mất mà không có đầu ra hoặc lưu trữ. | Đảm bảo mọi đầu vào đều dẫn đến đầu ra có ý nghĩa hoặc được lưu lại. |
| Logic điều khiển | Sử dụng sơ đồ luồng dữ liệu để thể hiện logic quyết định (nếu/else) thay vì luồng dữ liệu. | Sử dụng sơ đồ lưu đồ để kiểm soát logic; sử dụng sơ đồ luồng dữ liệu để thể hiện sự di chuyển dữ liệu. |
| Sơ đồ mất cân bằng | Sơ đồ con có đầu vào/đầu ra khác với sơ đồ cha. | Xem xét lại quá trình phân rã để đảm bảo mọi luồng dữ liệu đều được tính đến. |
| Quá trình ma quái | Các quá trình không thay đổi dữ liệu hoặc lưu trữ nó. | Loại bỏ các quá trình không thực hiện thay đổi nào. |
| Luồng trực tiếp giữa các thực thể | Dữ liệu chảy giữa hai thực thể bên ngoài mà không đi qua hệ thống. | Điều này nằm ngoài phạm vi hệ thống. Hệ thống phải xử lý tương tác này. |
Rất phổ biến khi nhầm lẫn sơ đồ luồng dữ liệu với các phương pháp vẽ sơ đồ khác. Mỗi công cụ phục vụ một mục đích cụ thể trong vòng đời phát triển phần mềm. Biết khi nào sử dụng sơ đồ nào sẽ giúp tránh nhầm lẫn.
Để đảm bảo sơ đồ của bạn vẫn là tài liệu hữu ích trong suốt vòng đời dự án, hãy tuân thủ các tiêu chuẩn này. Tính nhất quán là chìa khóa để duy trì tính toàn vẹn của mô hình yêu cầu.
Một trong những khía cạnh mạnh mẽ nhất của DFD được xây dựng tốt là khả năng hỗ trợ ma trận truy xuất nguồn gốc. Tính truy xuất nguồn gốc đảm bảo rằng mọi yêu cầu đều được đáp ứng và không có gì được xây dựng mà không có mục đích.
Khi bạn tạo một DFD, bạn có thể gán một ID duy nhất cho mỗi quá trình và kho dữ liệu. Ví dụ, quá trình P1.0 có thể tương ứng với Yêu cầu REQ-001. Nếu một bên liên quan yêu cầu tính năng mới, bạn có thể ánh xạ nó vào một ID quá trình cụ thể. Nếu bạn có thể tìm thấy quá trình trong sơ đồ, bạn sẽ biết chính xác nơi nào logic dữ liệu cần thay đổi.
Điều này đặc biệt quan trọng trong quá trình kiểm thử hồi quy. Nếu quá trình “Tính lãi suất” được sửa đổi, DFD sẽ cho đội QA biết chính xác luồng dữ liệu nào bị ảnh hưởng. Họ biết phải kiểm thử đầu vào (Số tiền gốc) và đầu ra (Tiền lãi thanh toán) một cách cụ thể. Không có DFD, người kiểm thử có thể bỏ sót các trường hợp biên liên quan đến chuyển đổi dữ liệu.
Một số đội cho rằng DFD quá nặng đối với các phương pháp Agile. Họ thích các câu chuyện người dùng và tiêu chí chấp nhận hơn. Mặc dù các câu chuyện người dùng rất tốt cho chức năng, nhưng chúng thường thiếu cái nhìn hệ thống về luồng dữ liệu. DFD phù hợp với Agile nếu được sử dụng như một tài liệu sống động.
Một DFD thường được kết hợp với Từ điển Dữ liệu. Từ điển Dữ liệu cung cấp định nghĩa kỹ thuật cho mọi phần tử dữ liệu được hiển thị trong sơ đồ. Nó xác định kiểu dữ liệu, độ dài và định dạng.
Ví dụ, một luồng dữ liệu được gán nhãn “Ngày sinh” trên sơ đồ có thể được định nghĩa trong từ điển là “YYYY-MM-DD, ISO 8601, Có thể rỗng”. Sự chính xác này ngăn cản các nhà phát triển đoán cách lưu trữ dữ liệu. Khi thu thập yêu cầu bao gồm cả DFD và Từ điển Dữ liệu, rủi ro sai lệch kiểu dữ liệu sẽ giảm đáng kể.
Hãy cân nhắc các thành phần sau cho Từ điển Dữ liệu của bạn:
Hành trình từ ý tưởng đến mã hóa đầy rẫy sự hiểu lầm. Sơ đồ luồng dữ liệu đóng vai trò như một lực ổn định trong hành trình này. Chúng buộc đội ngũ phải đối diện với thực tế về sự di chuyển dữ liệu. Chúng phơi bày những khoảng trống trong logic trước khi một dòng mã nào được viết ra.
Đầu tư thời gian để tạo ra các sơ đồ luồng dữ liệu chất lượng cao sẽ mang lại lợi ích bằng cách giảm thiểu công việc phải làm lại. Khi các bên liên quan xác nhận sơ đồ, họ đang xác nhận logic của hệ thống. Sự hiểu biết chung này làm giảm sự căng thẳng giữa các đội ngũ kinh doanh và công nghệ. Nó chuyển cuộc trò chuyện từ ý kiến cá nhân sang sự thật.
Hãy nhớ rằng sơ đồ luồng dữ liệu không phải là một tài liệu tĩnh. Nó thay đổi theo sự thay đổi của yêu cầu. Hãy đối xử với nó bằng sự nghiêm ngặt như đối với mã nguồn. Giữ cho nó được cập nhật, dễ tiếp cận và sử dụng nó để định hướng nỗ lực phát triển của bạn. Bằng cách thành thạo nghệ thuật mô hình hóa dữ liệu, bạn đảm bảo phần mềm bạn xây dựng không chỉ hoạt động được, mà còn hợp lý và phù hợp với nhu cầu của doanh nghiệp.
Sức mạnh ẩn giấu của sơ đồ luồng dữ liệu nằm ở sự đơn giản của nó. Chúng loại bỏ những tiếng ồn từ chi tiết triển khai và tập trung vào sự thật cốt lõi: dữ liệu phải được truyền tải đúng cách. Khi dữ liệu được truyền tải đúng, hệ thống sẽ hoạt động. Khi dữ liệu bị thiếu hoặc truyền sai hướng, hệ thống sẽ thất bại. Hãy sử dụng công cụ này để định hướng việc thu thập yêu cầu một cách tự tin và chính xác.