 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Tham gia thế giới kỹ thuật phần mềm thường đòi hỏi việc giải mã các bản vẽ phức tạp trước khi viết bất kỳ dòng mã nào. Trong số các sơ đồ được sử dụng để mô tả hành vi hệ thống, sơ đồ luồng dữ liệu (DFD) nổi bật như một công cụ quan trọng để hiểu cách thông tin di chuyển qua hệ thống. Khác với mã nguồn, vốn xác địnhcáchmột nhiệm vụ được thực hiện như thế nào, thì DFD minh họađiều gìdữ liệu được xử lý và nơi nó di chuyển. Đối với một kỹ sư mới, khả năng hiểu các sơ đồ này trực tiếp dẫn đến quá trình làm quen nhanh hơn, hiểu rõ hơn về kiến trúc hệ thống và cải thiện giao tiếp với các bên liên quan.
Hướng dẫn này được thiết kế để đưa bạn từ hiểu biết cơ bản về các ký hiệu đến khả năng tinh tế phân tích các luồng quy trình phức tạp. Chúng ta sẽ khám phá cấu tạo của một DFD, thứ bậc các cấp độ của nó, và những sai lầm phổ biến cho thấy lỗi mô hình hóa. Đến cuối hướng dẫn, bạn sẽ có một khung thực tiễn để đọc các sơ đồ này một cách tự tin và chính xác.
Sơ đồ luồng dữ liệu là một biểu diễn đồ họa về luồng dữ liệu qua một hệ thống thông tin. Nó mô hình hóa hệ thống theo góc nhìn chức năng, tập trung vào sự di chuyển của dữ liệu thay vì logic điều khiển hay thời gian. Sự phân biệt này rất quan trọng. Trong khi sơ đồ tuần tự thể hiện thứ tự các sự kiện, thì DFD thể hiện quá trình biến đổi dữ liệu từ đầu vào đến đầu ra.
Khi bạn nhìn vào một DFD, bạn thực chất đang xem một bản đồ về logic của hệ thống của mình. Bạn có thể xác định:
Nguồn gốc dữ liệu là ở đâu: Các nguồn hoặc thực thể bên ngoài hệ thống.
Dữ liệu thay đổi như thế nào: Các quy trình biến đổi dữ liệu đầu vào thành đầu ra.
Dữ liệu được lưu trữ ở đâu: Các kho dữ liệu nơi thông tin được lưu giữ.
Dữ liệu kết thúc ở đâu: Các điểm đến hoặc người nhận thông tin đã được xử lý.
Hiểu rõ mục đích này giúp bạn tránh được sai lầm phổ biến là cố gắng đọc DFD như một sơ đồ luồng. Trong DFD tiêu chuẩn không có vòng lặp, không có hình thoi quyết định, cũng không có trình tự theo thời gian. Đó là một bức ảnh tĩnh của sự di chuyển dữ liệu động. Sự trừu tượng này rất mạnh mẽ vì nó cho phép các kỹ sư thảo luận về yêu cầu hệ thống mà không bị mắc kẹt vào chi tiết triển khai.
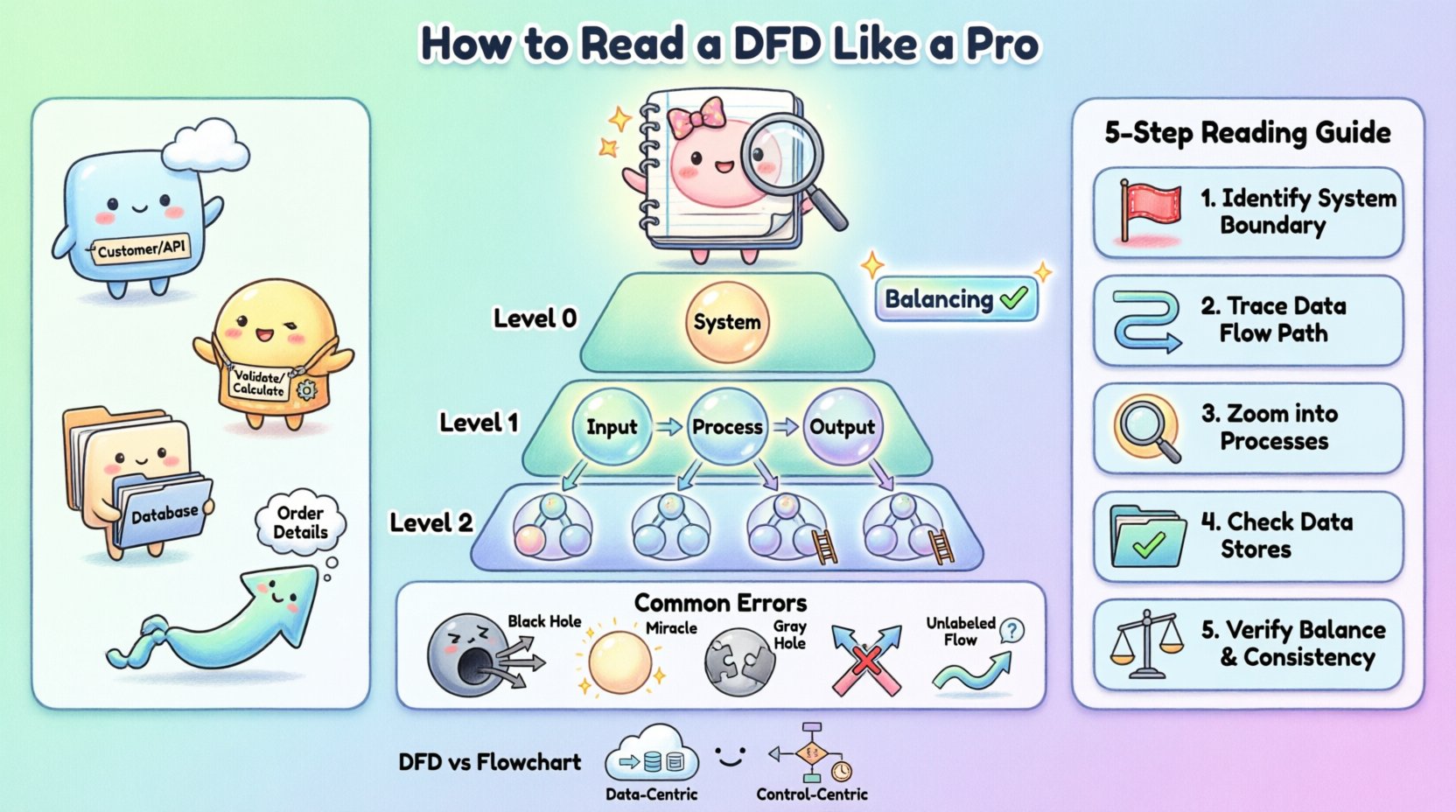
Để đọc DFD một cách thành thạo, bạn phải trước tiên nhận biết bốn thành phần cốt lõi của nó. Mặc dù các phong cách ký hiệu có chút khác biệt giữa các phương pháp, nhưng các khái niệm cốt lõi vẫn giữ nguyên. Bảng sau đây nêu rõ các thành phần này và cách biểu diễn hình ảnh tiêu chuẩn của chúng.
|
Thành phần |
Hình dạng hình ảnh |
Chức năng |
Ví dụ |
|---|---|---|---|
|
Thực thể bên ngoài |
Hình chữ nhật |
Nguồn hoặc điểm đến của dữ liệu bên ngoài hệ thống |
Khách hàng, Quản trị viên, API bên thứ ba |
|
Quy trình |
Hình tròn hoặc hình chữ nhật bo tròn |
Chuyển đổi dữ liệu đầu vào thành dữ liệu đầu ra |
Tính thuế, xác minh người dùng |
|
Kho dữ liệu |
Hình chữ nhật mở hoặc các đường song song |
Kho lưu trữ nơi dữ liệu được lưu trữ để sử dụng sau này |
Cơ sở dữ liệu khách hàng, tệp nhật ký |
|
Dòng dữ liệu |
Mũi tên |
Hướng và tên của dữ liệu di chuyển giữa các thành phần |
Chi tiết đơn hàng, xác nhận thanh toán |
Lưu ý rằng các nhãn trên các thành phần này không ngẫu nhiên. Quy tắc đặt tên là rất quan trọng để đảm bảo rõ ràng. Một quá trình nên được đặt tên bằng động từ và danh từ (ví dụ: “Cập nhật kho hàng”), thể hiện hành động được thực hiện trên dữ liệu. Một kho dữ liệu nên đại diện cho một danh từ (ví dụ: “Nhật ký kho hàng”), tượng trưng cho một tập hợp các bản ghi. Các luồng dữ liệu phải được đặt tên để mô tả nội dung cụ thể đang di chuyển theo mũi tên.
Các hệ thống phức tạp không thể được biểu diễn trong một sơ đồ duy nhất mà không trở nên khó đọc. Để quản lý độ phức tạp, DFD được cấu trúc theo thứ bậc. Cách tiếp cận này cho phép bạn thu nhỏ hoặc phóng to hệ thống, tập trung vào logic cấp cao hoặc chi tiết cụ thể khi cần thiết.
Sơ đồ bối cảnh cung cấp mức độ trừu tượng cao nhất. Nó thể hiện hệ thống như một bong bóng quá trình duy nhất và minh họa cách nó tương tác với các thực thể bên ngoài. Ở đây không có kho dữ liệu nội bộ hay các quá trình con nào được hiển thị. Mục tiêu là xác định ranh giới của hệ thống. Bạn sẽ thấy hệ thống ở trung tâm, bao quanh bởi các thực thể cung cấp dữ liệu cho hệ thống và nhận dữ liệu từ hệ thống. Đây là sơ đồ đầu tiên bạn nên xem để hiểu phạm vi của dự án.
Cũng được gọi là Sơ đồ cấp cao nhất, sơ đồ này chia bong bóng hệ thống duy nhất từ Sơ đồ bối cảnh thành các hệ thống con chính hoặc các quá trình chính. Nó tiết lộ các kho dữ liệu chính và luồng dữ liệu cấp cao giữa các chức năng chính này. Mức độ này rất quan trọng để hiểu các mô-đun chính của phần mềm và cách chúng liên quan đến nhau.
Các sơ đồ này đại diện cho việc phân rã sâu hơn. Sơ đồ cấp độ 1 chi tiết hóa các quá trình được hiển thị trong sơ đồ cấp độ 0. Sơ đồ cấp độ 2 đi sâu hơn vào một quá trình cụ thể từ cấp độ 1. Khi bạn đi xuống theo thứ bậc, số lượng quá trình và kho dữ liệu sẽ tăng lên. Tuy nhiên, mỗi quá trình riêng lẻ trên sơ đồ cấp thấp hơn phải nhất quán với đầu vào và đầu ra của quá trình cha trên cấp cao hơn.
Khái niệm này được gọi là cân bằng. Nếu một quá trình cấp độ 0 có đầu vào là “Dữ liệu đơn hàng” và đầu ra là “Biên lai”, thì mọi quá trình con trong quá trình phân rã phải cùng nhau đảm bảo việc nhận “Dữ liệu đơn hàng” và tạo ra “Biên lai”. Sự nhất quán này là dấu hiệu quan trọng của một mô hình được xây dựng tốt.
Khi bạn được đưa một DFD cho một tính năng mới hoặc một hệ thống cũ, đừng cố gắng ghi nhớ toàn bộ hình ảnh cùng một lúc. Thay vào đó, hãy sử dụng phương pháp theo dõi có hệ thống. Điều này đảm bảo bạn không bỏ sót các kết nối hoặc hiểu sai logic.
Bước 1: Xác định ranh giới.Tìm các thực thể bên ngoài. Đây là điểm bắt đầu và kết thúc. Hãy tự hỏi bản thân: “Ai đang tương tác với hệ thống này?” Nếu một quá trình không có kết nối với thực thể bên ngoài hoặc kho dữ liệu, nó có thể là một thành phần tách biệt cần được giải thích thêm.
Bước 2: Theo dõi luồng dữ liệu.Chọn một đầu vào cụ thể, chẳng hạn như một “Yêu cầu đăng nhập”. Theo dõi mũi tên từ Thực thể đến Quá trình. Sau đó theo mũi tên đầu ra đến quá trình tiếp theo hoặc kho dữ liệu. Đừng nhảy qua lại trên sơ đồ; hãy theo một đường đi tại một thời điểm.
Bước 3: Phân tích các quá trình. Với mỗi bọt quy trình, hãy hỏi: ‘Chuyển đổi là gì?’ Liệu đầu vào có phù hợp với đầu ra về mặt logic không? Ví dụ, nếu một quy trình có tên là ‘Tính Chiết khấu’, hãy đảm bảo đầu vào bao gồm ‘Giá’ và ‘Trạng thái Thành viên’. Nếu thiếu đầu vào, sơ đồ sẽ không đầy đủ.
Bước 4: Xác minh Các Kho Dữ liệu. Đảm bảo rằng mỗi kho dữ liệu có ít nhất một thao tác đọc (luồng đầu vào) và một thao tác ghi (luồng đầu ra), trừ khi đó là một bản ghi cố định chỉ được cập nhật thỉnh thoảng. Một kho dữ liệu chỉ nhận dữ liệu nhưng chưa bao giờ phát ra có thể là lỗi ‘bể nước’, trong khi một kho chỉ phát ra dữ liệu có thể là lỗi ‘nguồn’.
Bước 5: Kiểm tra Cân bằng. Nếu bạn đang xem sơ đồ cấp 1, hãy xác minh nó với sơ đồ cấp 0 cha. Các đầu vào và đầu ra có khớp nhau không? Nếu quy trình cha nói ‘Nhận Đơn hàng’, thì quy trình con cũng phải nhận dữ liệu ‘Đơn hàng’. Nếu quy trình con lại nhận ‘Thanh toán’ thay vì vậy, sơ đồ sẽ mất cân bằng.
Bằng cách tuân theo trình tự này, bạn sẽ chuyển từ góc nhìn vĩ mô sang góc nhìn vi mô, đảm bảo hiểu rõ toàn diện về kiến trúc hệ thống.
Ngay cả các kỹ sư có kinh nghiệm cũng mắc sai lầm khi tạo sơ đồ luồng dữ liệu (DFD). Là người đọc, việc phát hiện những bất thường này có thể giúp bạn tiết kiệm thời gian đáng kể trong quá trình phát triển. Nhận diện những lỗi này giúp bạn đặt ra những câu hỏi đúng đắn cho các kiến trúc sư hệ thống.
Hố đen xảy ra khi một quy trình có đầu vào nhưng không có đầu ra. Dữ liệu đi vào quy trình và biến mất. Trong hệ thống thực tế, điều này ngụ ý dữ liệu đang bị mất. Ví dụ, nếu một ‘Xử lý Người dùng’ nhận ‘Mẫu Đăng nhập’ nhưng không tạo ra đầu ra nào cho cơ sở dữ liệu hay màn hình xác nhận, dữ liệu sẽ không có nơi nào để đi. Điều này cho thấy yêu cầu bị thiếu hoặc đường logic bị hỏng.
Kỳ diệu là điều ngược lại với hố đen. Đó là một quy trình tạo ra đầu ra mà không nhận bất kỳ đầu vào nào. Làm sao một hệ thống có thể tạo ra ‘Báo cáo Bán hàng’ mà không đọc ‘Dữ liệu Bán hàng’? Điều này ngụ ý dữ liệu đang được tạo ra từ hư không, điều không thể xảy ra trong một hệ thống xác định. Đầu vào bị thiếu phải được xác định và kết nối với một kho dữ liệu hoặc một thực thể bên ngoài.
Lỗi này xảy ra khi đầu vào và đầu ra của một quy trình không phù hợp về mặt logic, ngay cả khi cả hai đều tồn tại. Ví dụ, nếu một quy trình có tên là ‘Tính Thuế’ nhưng đầu vào là ‘Địa chỉ Người dùng’ và đầu ra là ‘Tổng Giá’, thì quá trình chuyển đổi là chưa hoàn chỉnh. Tỷ lệ thuế bị thiếu. Điều này thường chỉ ra kho dữ liệu bị thiếu hoặc luồng chưa được kết nối.
Trong các sơ đồ DFD sạch sẽ, các mũi tên không nên giao nhau mà không có kết nối. Nếu hai luồng dữ liệu giao nhau, có thể gây nhầm lẫn về việc chúng có tương tác hay chỉ đi ngang qua nhau. Mặc dù một số giao nhau là không thể tránh khỏi trong các sơ đồ phức tạp, nhưng điều đó là dấu hiệu của bố cục kém. Trong một sơ đồ được thiết kế tốt, các luồng phải được định tuyến rõ ràng để tránh nhầm lẫn.
Mỗi mũi tên đều phải có nhãn. Một mũi tên không có tên ngụ ý rằng nội dung dữ liệu cụ thể là chưa biết. Nếu bạn thấy một mũi tên kết nối giữa Kho Dữ liệu và Quy trình, bạn phải biết dữ liệu nào đang được truy xuất. ‘Dữ liệu’ không phải là nhãn đủ cụ thể. Nó nên là ‘Danh sách Khách hàng’ hoặc ‘Token Phiên Hoạt’. Các nhãn mơ hồ là nguyên nhân chính gây lỗi triển khai.
Một trong những điểm gây nhầm lẫn phổ biến nhất đối với các kỹ sư mới là sự khác biệt giữa Sơ đồ Luồng Dữ liệu và Sơ đồ Lưu đồ. Mặc dù cả hai đều sử dụng hình dạng và mũi tên, nhưng ý nghĩa của chúng hoàn toàn khác nhau.
Trọng tâm: Một Sơ đồ Lưu đồ tập trung vào luồng điều khiển. Nó thể hiện thứ tự các thao tác, các điểm quyết định (nếu/else) và vòng lặp. Nó trả lời câu hỏi ‘Việc gì xảy ra tiếp theo?’ Một DFD tập trung vào luồng dữ liệu. Nó thể hiện sự di chuyển của thông tin. Nó trả lời câu hỏi ‘Dữ liệu đi đâu?’
Lôgic so với Dữ liệu: Trong một Sơ đồ Lưu đồ, bạn sẽ thấy các hình thoi quyết định. Trong một DFD tiêu chuẩn, bạn sẽ không thấy. Một DFD giả định quy trình xảy ra; nó không mô hình hóa logic nhánh bên trong quy trình đó.
Thời gian: Sơ đồ Lưu đồ thường ngụ ý một trình tự theo thời gian. DFD thường không có thời gian. Một DFD không cho thấy quy trình nào xảy ra trước, trừ khi được ngụ ý bởi các phụ thuộc dữ liệu.
Bộ nhớ:Sơ đồ luồng thường không hiển thị rõ ràng việc lưu trữ dữ liệu. Các sơ đồ luồng dữ liệu (DFD) mô hình hóa rõ ràng các kho lưu trữ dữ liệu như một thành phần cốt lõi.
Hiểu được sự khác biệt này sẽ ngăn bạn cố tìm kiếm logic điều khiển ở nơi không tồn tại. Nếu bạn đang tìm kiếm logic kiểu ‘nếu điều này thì làm điều kia’, hãy xem sơ đồ luồng hoặc mã giả. Nếu bạn đang tìm nơi cơ sở dữ liệu được cập nhật, hãy xem DFD.
Việc đọc DFD không chỉ là bài tập học thuật; đó là yêu cầu hàng ngày đối với các kỹ sư phần mềm. Dưới đây là cách kỹ năng này được áp dụng vào các tình huống thực tế.
1. Chào mừng và kiểm tra mã nguồn:Khi tham gia một nhóm mới, tài liệu kiến trúc thường bao gồm các DFD. Việc đọc chúng giúp bạn hiểu được các mối phụ thuộc dữ liệu trước khi thao tác với mã nguồn. Trong quá trình kiểm tra mã, bạn có thể kiểm tra xem việc triển khai có khớp với sơ đồ hay không. Nếu sơ đồ cho thấy dữ liệu đi đến bộ nhớ đệm, nhưng mã nguồn chỉ ghi vào cơ sở dữ liệu, bạn đã phát hiện ra sự bất nhất.
2. Gỡ lỗi và khắc phục sự cố:Khi một tính năng bị lỗi, DFD sẽ giúp bạn truy vết hành trình của dữ liệu. Nếu người dùng báo rằng hồ sơ của họ không được cập nhật, bạn có thể theo dõi luồng ‘Cập nhật hồ sơ’ trên DFD. Bạn có thể kiểm tra các quá trình tham gia và các kho lưu trữ dữ liệu được truy cập. Điều này giúp thu hẹp đáng kể không gian tìm kiếm so với việc tìm kiếm mã nguồn một cách mù quáng.
3. Thu thập yêu cầu:Khi làm việc với các quản lý sản phẩm, bạn thường cần trực quan hóa các yêu cầu. Nếu bạn hiểu DFD, bạn có thể giúp tinh chỉnh các yêu cầu. Bạn có thể phát hiện các luồng dữ liệu bị thiếu hoặc các phép biến đổi không thể thực hiện trước khi phát triển bắt đầu. Cách tiếp cận chủ động này giúp giảm nợ kỹ thuật.
4. Tích hợp hệ thống:Trong kiến trúc microservices, DFD là thiết yếu để xác định hợp đồng API. Bạn có thể bản đồ luồng dữ liệu giữa các dịch vụ để đảm bảo đầu ra của Dịch vụ A tương thích với đầu vào của Dịch vụ B. Điều này ngăn ngừa các lỗi tích hợp do định dạng dữ liệu không khớp.
Để đảm bảo các sơ đồ bạn đọc vẫn hữu ích theo thời gian, hãy cân nhắc các thực hành sau. Một sơ đồ lỗi thời còn tệ hơn cả việc không có sơ đồ nào.
Giữ ở mức độ cao:Đừng làm rối DFD bằng tên của mọi biến. Hãy tập trung vào các thực thể dữ liệu mang tính logic. ‘Dữ liệu đầu vào từ người dùng’ tốt hơn ‘Giá trị trường tên’.
Sử dụng tên nhất quán:Đảm bảo rằng ‘Khách hàng’ trong một sơ đồ được gọi là ‘Khách hàng’ trong tất cả các sơ đồ liên quan. Tránh dùng từ đồng nghĩa như ‘Khách hàng’ hoặc ‘Người dùng’ trừ khi chúng đại diện cho các thực thể khác nhau.
Cập nhật trong quá trình thay đổi:Nếu mã nguồn thay đổi đáng kể, DFD cần được cập nhật. Một sơ đồ được kiểm soát phiên bản có thể đóng vai trò như lịch sử phát triển của hệ thống.
Hạn chế độ phức tạp:Nếu một sơ đồ trở nên quá chật chội, đã đến lúc phân tách nó thành các sơ đồ cấp thấp hơn. Một quy tắc tốt là sơ đồ cấp 0 nên có không quá 7 đến 10 quá trình chính.
Thành thạo việc diễn giải Sơ đồ Luồng Dữ liệu đòi hỏi sự kiên nhẫn và luyện tập. Điều này bao gồm việc vượt ra ngoài các ký hiệu để hiểu được các mối quan hệ logic giữa chúng. Bằng cách tập trung vào sự di chuyển của dữ liệu, phát hiện các bất thường và hiểu rõ cấu trúc phân cấp, bạn trang bị cho bản thân một công cụ mạnh mẽ để phân tích hệ thống.
Khi bạn tiến bộ trong sự nghiệp kỹ thuật, bạn sẽ gặp nhiều kỹ thuật mô hình hóa khác nhau. DFD vẫn là kỹ năng nền tảng. Nó dạy bạn suy nghĩ về hệ thống theo các khía cạnh đầu vào, biến đổi và đầu ra. Tư duy này có thể áp dụng sang thiết kế cơ sở dữ liệu, kiến trúc API và lập kế hoạch hạ tầng đám mây. Tiếp tục luyện tập đọc các sơ đồ này trong các dự án mã nguồn mở hoặc tài liệu nội bộ. Càng theo dõi nhiều luồng dữ liệu, kiến trúc hệ thống sẽ càng trở nên trực quan hơn với bạn.