 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











データフローダイアグラム(DFD)を作成することは、システム分析における重要な節目です。DFDは、データがシステム内でどのように移動するかをマッピングし、情報がどのように処理され、保存され、転送されるかを定義します。しかし、視覚的に魅力的な図であっても、機能的に正確とは限りません。検証は、論理的な誤りがなく、システム要件を正しく表現しているかを確認する重要な段階です。このプロセスにより、データフローが一貫性を持ち、プロセスがバランスが取れており、構造が意図されたビジネスロジックを支えることを保証します。
検証は単一の行動ではなく、厳密なレビューです。すべての要素を確立されたルールと照らし合わせて確認する体系的なアプローチが必要です。構造化されたレビュー手順に従うことで、曖昧さを排除し、図が開発およびステークホルダーとのコミュニケーションの信頼できるブループリントとして機能することを保証できます。このガイドは、DFDを効果的に検証するために必要な包括的なステップを示しており、システム設計全体にわたり正確性と一貫性を確保します。
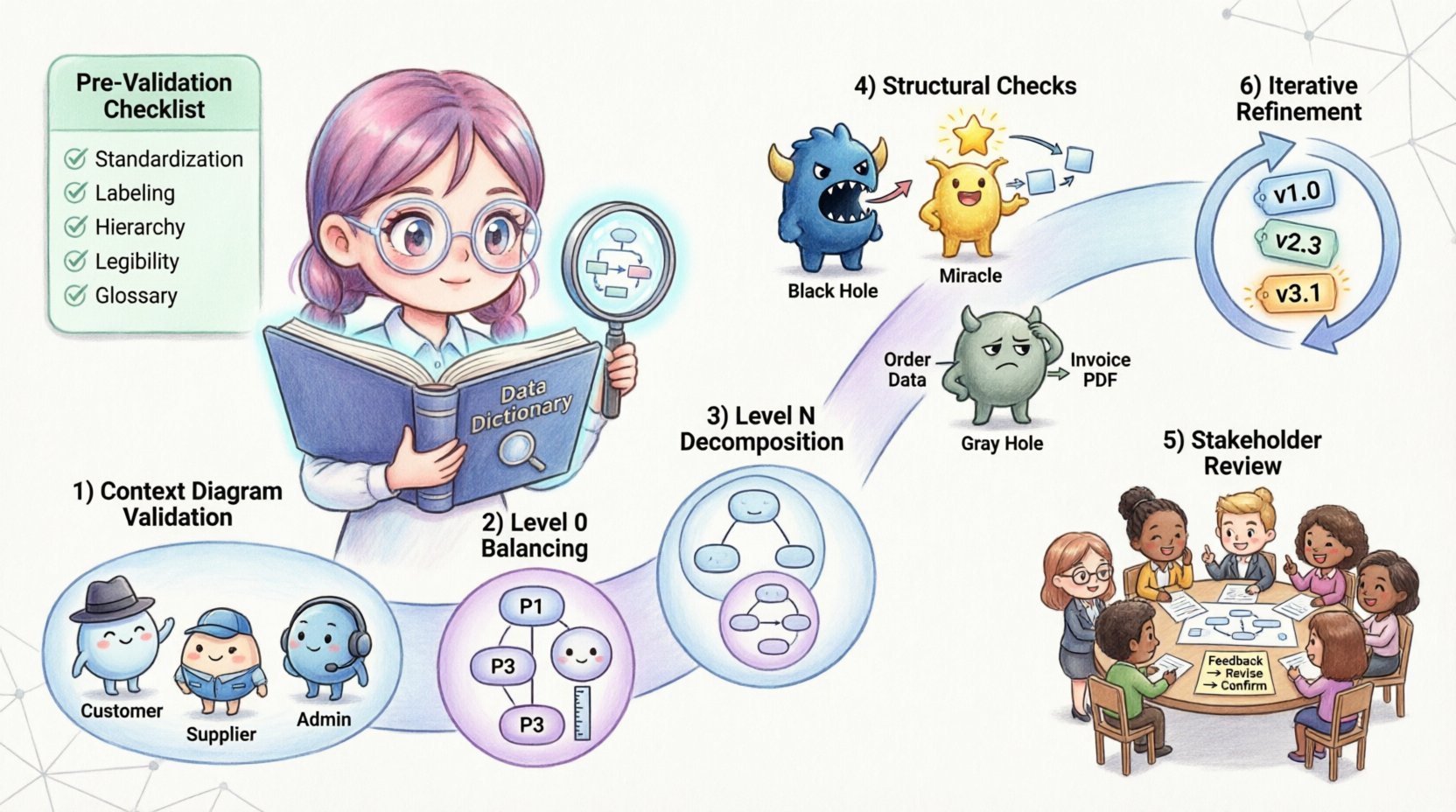
具体的なステップに入る前に、システム設計の文脈で検証が達成する目的を理解することが不可欠です。検証は「私たちは正しい製品を構築しているか?」と問います。検証は「私たちは正しい製品を構築しているか?」と問います。DFDの文脈では、検証は抽象的な要件と具体的なシステム動作の間のギャップを埋めます。
検証されたDFDは以下のことを保証します:
この段階を飛ばすと、開発段階で高コストの再作業を引き起こすことがよくあります。データフローが欠落している、またはデータストアが定義されていないといった問題は、コードが書かれた段階で修正すると非常に高価になります。厳密なレビュー手順により、これらのリスクを早期に軽減できます。
正式なレビューを開始する前に、図が検証に耐える準備ができていることを確認してください。ごちゃごちゃしている、または整理されていない図は検証を難しくします。以下のチェックリストを使って、作業を準備してください:
コンテキスト図は、最も高い抽象度の図です。システムを単一のプロセスとして示し、外部エンティティとの相互作用を表します。これは検証における最初の防衛線です。
外部エンティティは、システムの境界外にあるデータの発生源または到着先を表します。表示されているすべてのエンティティが必要であり、明確に定義されていることを確認してください。以下の質問を検討してください:
システムを表す単一のプロセスには、すべての内部論理が含まれている必要があります。データフローがこのプロセスを経由せずに境界を越えることがないかを検証してください。データがシステムにアクセスせずに、外部エンティティから別の外部エンティティへ移動する場合は、コンテキスト図に表示してはいけません。これは範囲外の動作であるためです。
中心プロセスに接続されているすべての矢印を確認してください。各入力には、対応する出力または保存処理が存在する必要があります。データフローがシステムに入力されるが、出力されるデータがない場合、データが目的もなく消失する「ブラックホール」プロセスを示している可能性があります。
レベル0 DFDは、コンテキスト図の単一プロセスを主要なサブシステムに分解します。ここでの最も重要なルールはバランスです。親プロセスの入力と出力は、子プロセスの入力と出力と完全に一致している必要があります。
コンテキスト図のプロセスに入力されるすべてのデータフローに対して、レベル0図にも対応するデータフローが入力されている必要があります。出力についても同様です。これをデータ保存と呼びます。コンテキスト図で「顧客注文」がシステムに入力されている場合、レベル0図では少なくとも1つの主要プロセスに「顧客注文」が入力されている必要があります。
レベル0には通常、3~7つのプロセスが含まれます。7つを超える場合は、1つのビューで扱うには図が複雑すぎる可能性があります。3つ未満の場合は、さらに分解する必要があるかもしれません。各プロセスが明確に区別され、単一の論理的機能を実行していることを確認してください。
レベル0のすべてのデータストアが必要であることを確認してください。データストアは、後で使用するためにデータを保持する必要がある場合にのみ存在すべきです。ストアへのデータフローとストアからのデータフローが正しくラベル付けされていることを確認してください。データストアは外部エンティティに直接接続してはいけません。すべてのデータはプロセスを経由して移動しなければなりません。
レベルNの図は、レベル0で特定された特定のプロセスについて、さらに詳細を提供します。このレベルでの検証は、親プロセスとの整合性に焦点を当てます。
レベル0と同様に、親プロセスの入力と出力は、子プロセスの集約された入力と出力と一致している必要があります。レベル0図でプロセス1.0が「ログインデータ」を入力し、「アクセストークン」を出力する場合、プロセス1.0のレベル1分解図でも「ログインデータ」を受け入れ、同じく「アクセストークン」を出力する必要があります。
分解が論理的であることを確認してください。子図は親プロセスがどのように動作するかを説明していますか?どのように親プロセスがどのように動作するかを説明していますか?親プロセスに示唆されていない新しい外部エンティティやデータストアを子図に導入しないようにしてください。新しいデータストアを導入する場合は、データを保持する必要があるという要件によって正当化される必要があります。
子図のデータフローのラベルは、該当する場合は親図のラベルと一致している必要があります。フローが子図で詳細化された場合(例:「データ」が「ユーザー情報」に変更された)には、変更がデータ辞書と整合している必要があります。ここでの曖昧さは、実装段階で混乱を招く原因になります。
DFD設計に誤りを示す特定の構造的異常があります。これらの一般的なパターンは、検証中に特定され、修正される必要があります。
ブラックホールプロセスとは、入力はあるが出力がないプロセスを指す。データはプロセスに入り、消えてしまう。これは通常、出力フローが欠落しているか、プロセス定義が不完全であることを示している。すべてのプロセスは、保存されるデータ、他の場所に送信されるデータ、または意思決定の結果といった何らかの結果を生成しなければならない。
ミラクルプロセスとは、出力はあるが入力がないプロセスを指す。何もかもからデータを創り出す。これはシステム設計において論理的に不可能である。すべての出力は、入力データから生成され、または保存されたデータから導出されなければならない。
グレイホールとは、入力と出力が論理的に一致しないときに発生する。たとえば、入力が「顧客住所」で出力が「支払い詳細」の場合、プロセスは単なる変換以上のことを行っていることになる。入力から導出できないデータを作り出しているのである。これは、データフローが欠落しているか、データストアが欠落していることを示唆している。
外部エンティティからデータストアへ直接データフローが行くことを確認する。ストアに入出するすべてのデータは、プロセスを経由しなければならない。これにより、データの整合性ルールやビジネスロジックが保存前に適用されることが保証される。
レビューの際にこの表を素早い参照として活用してください。各要素に必要な主なルールとチェック項目を要約しています。
| 要素 | 検証ルール | 一般的な誤り |
|---|---|---|
| プロセス | 少なくとも1つの入力と1つの出力を持つ必要がある | ブラックホールプロセスまたはミラクルプロセス |
| データストア | プロセスに接続されている必要がある。エンティティに接続してはならない | エンティティからストアへの直接フロー |
| データフロー | 名詞句でラベル付けされなければならない | 動詞のラベルまたはラベルなし |
| 外部エンティティ | システム境界の外にある必要がある | システム境界内のエンティティ |
| 整合性 | 親と子の入力/出力は一致している必要がある | バランスの取れていないデータフロー |
| 分解 | 子要素は「なぜ」ではなく「どうやって」を説明しなければならない | 範囲外の論理の追加 |
検証は単なる技術的チェックではなく、コミュニケーションツールである。技術的なルールが満たされた後は、図がビジネスニーズを満たしているかを確認するためにステークホルダーによるレビューが必要である。
図を孤立して提示してはならない。データの流れを説明するウォークスルーを準備する。特定のデータストアが存在する理由や、プロセスがどのように相互作用するかの文脈を提供する。すべてのステークホルダーが用語を理解できるように、データ辞書へのアクセスを確保する。
ステークホルダーに流れに対して質問するよう促す。次のような具体的な質問を投げかける。
すべてのフィードバックと提案された変更を記録する。ステークホルダーが新しいデータフローを提案した場合、受け入れる前にバランスルールに基づいて検証する。図とデータ辞書を同時に更新して同期を保つ。バージョン管理は不可欠であり、各レビュー回の図の状態を記録しておく必要がある。
検証はほとんど一度限りの出来事ではない。要件が進化するにつれて、DFDもそれに合わせて進化しなければならない。このセクションでは、プロジェクトのライフサイクル中に変更を管理する方法について説明する。
変更が要求された際には、その変更が全体の階層に与える影響を分析する。レベル1のプロセスが変更された場合、レベル0に影響するか?新しいデータストアが必要か?同じデータフローを共有する他のプロセスに影響するか?この影響分析を行うことで、連鎖的なエラーを防ぐことができる。
図の改訂履歴を明確に保つ。バージョン番号(例:v1.0、v1.1)と改訂日を用いる。これにより、チームはシステム設計の進化を追跡でき、必要に応じて変更を元に戻すことができる。特定のツールは必須ではないが、ファイルに対して厳格な命名規則を設けることは不可欠である。
変更を実装した後は、検証プロセスを再実行する。小さな変更が全体の整合性を保つとは限らない。バランスルール、命名規則、構造的整合性を再確認する必要がある。小さな追加が、以前に検証済みの図のバランスを崩すことがある。
データ辞書はDFDの骨格である。すべてのデータ要素の構造を定義する。検証は視覚的な図にとどまらず、テキストによる定義にも及びなければならない。
図上のデータフローのラベルが、辞書のエントリと正確に一致していることを確認する。図では「Invoice ID」と記載されているが、辞書では「Invoice Identifier」となっている場合、データベース設計の段階で混乱を招く可能性がある。すべての文書で用語を統一する。
すべてのデータストアが辞書に定義された構造を持っているかを確認する。属性、データ型、キー制約をリストアップする。DFDで参照されているデータストアに辞書のエントリがない場合、設計は不完全である。このギャップは後でデータベースエラーを引き起こすことが多い。
図に示された暗黙のデータ型が、ビジネスルールと一致しているかを検証する。たとえば、「生年月日」を表すデータフローは、辞書ではテキスト文字列として扱われてはならない。日付形式でなければならない。このレベルの詳細が、技術的実装と概念設計の整合性を保つ。
経験豊富なアナリストですら、検証プロセス中に特定の罠に陥ることがある。これらの一般的な落とし穴を認識しておくことで、レビューをより効果的に進めることができる。
検証が完了したら、開発チームへの引き渡し用にドキュメントを最終化しなければならない。これには図面、データ辞書、検証レポートのまとめが含まれる。
すべてのレベル0の図、レベルNの図、およびコンテキスト図を1つのパッケージにまとめる。開発者が分解の流れを追えるように、階層構造が明確に示されていることを確認する。データ辞書を補足文書として含める。
検証プロセスの要約レポートを作成する。レビュー中に発見された問題とその解決方法をリストアップする。この文書は設計が検証された証拠となる。また、初期レビューに参加していなかった将来の保守担当者にとっても、背景情報を提供する。
検証済みDFDの引き渡しプロセスを定義する。開発チームに設計を説明する会議を含めるべきである。曖昧なデータフローまたは複雑なデータストアに関する質問に答える。DFDがデータ要件の真実の出所であることをチームが理解していることを確認する。
検証で終わるのではなく、システムが進化する中でも図は正確なまま保たれるべきである。将来の変更に対してガバナンスプロセスを確立する。
これらの検証ステップに従うことで、データフローダイアグラムがシステムライフサイクル全体で堅牢で正確かつ有用であることを保証できる。この規律により曖昧さが減少し、高コストの誤りを防ぎ、成功したシステム開発の基盤を築くことができる。