 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











ソフトウェアエンジニアリングの世界に入ることは、1行のコードも書く前に複雑な図面を解読する必要があることが多い。システムの動作をマッピングするために用いられるさまざまな図のなかで、データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを理解するための重要なツールとして際立っている。コードが「」を規定するのに対し、どのようにタスクがどのように実行されるかを規定するのに対し、DFDは「」を示す。何がデータが処理される内容とその移動先を示す。新米エンジニアにとって、これらの図を解釈できる力は、即座に業務に慣れる、システムアーキテクチャの理解が深まる、ステークホルダーとのコミュニケーションが向上するという直接的な利点につながる。
このガイドは、記号の基本的な理解から始めて、複雑なプロセスフローを分析する高度な能力へと導くことを目的としています。DFDの構造、レベルの階層、そしてモデル化エラーを示す一般的な落とし穴について検討します。最終的には、これらの図を自信を持って正確に読み解くための実用的なフレームワークを身につけるでしょう。
データフローダイアグラムは、情報システム内を流れるデータの流れを視覚的に表現したものです。これは、制御論理やタイミングではなく、データの移動に注目した機能的視点からシステムをモデル化するものです。この違いは非常に重要です。シーケンス図がイベントの順序を示すのに対し、DFDは入力から出力へのデータの変換を示します。
DFDを見ると、実質的にシステムの論理を地図として見ていることになります。次のような点を特定できます:
データが発生する場所:外部のソースまたはエンティティ。
データがどのように変化するか:入力を出力に変換するプロセス。
データが一時的に保管される場所:情報が保管されるデータストア。
データが最終的に到達する場所:処理された情報の宛先または受信者。
この目的を理解することで、DFDをフローチャートのように読みようとする一般的な誤りを避けられます。標準的なDFDにはループも、決定のダイアモンドも、時間に基づく順序も存在しません。これは、動的なデータ移動を静的なスナップショットとして捉えたものです。この抽象化は強力であり、エンジニアが実装の詳細に巻き込まれることなく、システム要件について議論できるようにするからです。
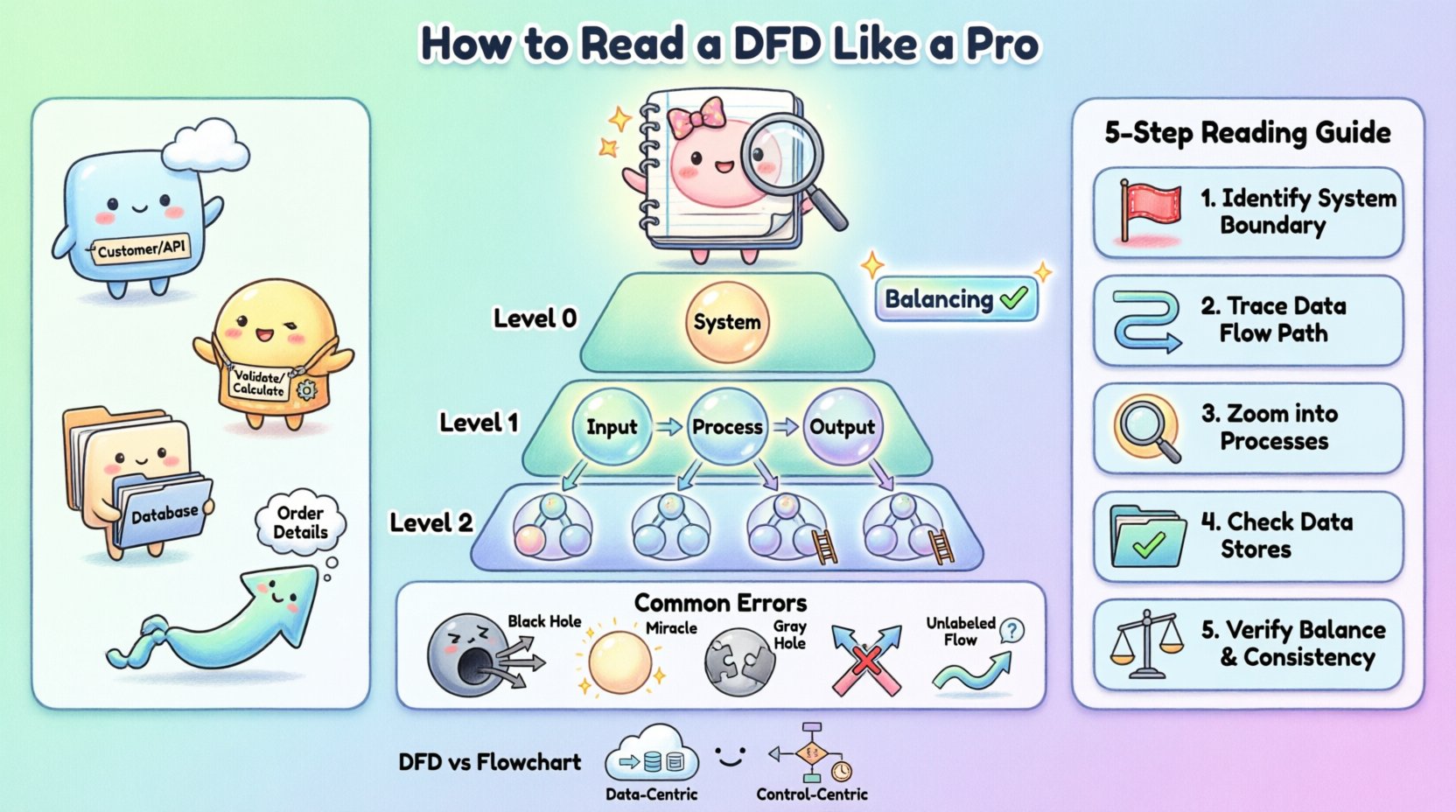
DFDを上手に読み解くためには、まずその4つの基本構成要素を認識することが必要です。表記スタイルはメソドロジーによってわずかに異なりますが、基本的な概念は一貫しています。以下の表は、これらの要素とその標準的な視覚的表現を示しています。
|
構成要素 |
視覚的形状 |
機能 |
例 |
|---|---|---|---|
|
外部エンティティ |
長方形 |
システム外のデータの発生源または到着先 |
顧客、管理者、サードパーティAPI |
|
プロセス |
円または角が丸い長方形 |
入力データを出力データに変換する |
税額を計算する、ユーザーを検証する |
|
データストア |
開いた長方形または平行線 |
後で使用するためにデータが格納されるリポジトリ |
顧客データベース、ログファイル |
|
データフロー |
矢印 |
コンポーネント間を移動するデータの方向と名前 |
注文詳細、支払い確認 |
これらのコンポーネントのラベルは任意ではないことに注意してください。命名規則は明確さにとって不可欠です。プロセスは動詞と名詞で名前を付けるべきです(例:「在庫を更新する」)。「データに対して実行される操作」を示します。データストアは名詞で表すべきです(例:「在庫ログ」)。「レコードの集まり」を表します。データフローは、矢印に沿って移動する具体的な内容を説明するように名前を付ける必要があります。
複雑なシステムは、単一の図に表現すると読みにくくなるため、1枚の図に収めることはできません。複雑さを管理するために、DFDは階層的に構造化されています。このアプローチにより、システムの高レベルな論理や詳細な部分に焦点を当てて、必要に応じてズームイン・ズームアウトが可能になります。
コンテキスト図は、最も高い抽象度を提供します。システムを1つのプロセスバブルとして示し、外部エンティティとの相互作用を説明します。ここでは内部のデータストアやサブプロセスは表示されません。目的はシステムの境界を定義することです。システムが中心にあり、データを供給するか、データを受け取る外部エンティティがその周囲に配置されている様子が見えます。プロジェクトの範囲を理解するためには、まずこの図を確認するべきです。
トップレベル図とも呼ばれるこの図は、コンテキスト図の単一のシステムバブルを、主要なサブシステムまたは主要なプロセスに分解します。主要なデータストアと、これらの主要機能間を流れるデータの高レベルなフローを明らかにします。このレベルは、ソフトウェアの主要モジュールとそれらの関係を理解するために不可欠です。
これらの図は、さらに分解を表しています。レベル1図は、レベル0図に示されたプロセスを詳細に記述します。レベル2図は、レベル1の特定のプロセスをさらに深く掘り下げます。階層を下るにつれて、プロセスとデータストアの数が増加します。しかし、低レベルの図上の個々のプロセスは、上位レベルの親プロセスの入力と出力と整合している必要があります。
この概念は「バランス」と呼ばれます。レベル0のプロセスが「注文データ」を入力として受け取り、「領収書」を出力する場合、分解されたすべての子プロセスが、 collectively して「注文データ」を受け取り、「領収書」を生成しなければなりません。この整合性は、適切に構築されたモデルの重要な指標です。
新しい機能やレガシーシステムのDFDが渡されたときは、一度に全体の図を暗記しようとしないでください。代わりに、体系的なトレース法を使用してください。これにより、接続を見逃したり、論理を誤解したりするのを防げます。
ステップ1:境界を特定する。外部エンティティを探してください。これらが開始点と終了点です。自分に問いかけてください。「このシステムとやり取りしているのは誰ですか?」プロセスが外部エンティティやデータストアに接続されていない場合、それは孤立したコンポーネントであり、さらに説明が必要な可能性があります。
ステップ2:データフローを追跡する。特定の入力、たとえば「ログインリクエスト」を選んでください。エンティティからプロセスへの矢印に従って進みます。次に、出力矢印に従って次のプロセスまたはデータストアへ進みます。図の上で飛び跳ねず、一度に1つの経路だけを追跡してください。
ステップ3:プロセスを分析する。 各プロセスのバブルについて、「変換とは何か?」と尋ねてください。入力が論理的に出力と一致しているか確認してください。たとえば、プロセスが「割引を計算する」と名付けられている場合、「価格」と「会員ステータス」が入力に含まれていることを確認してください。入力が不足している場合は、図は不完全です。
ステップ4:データストアの確認。すべてのデータストアが、少なくとも1つの読み取り操作(入力フロー)と1つの書き込み操作(出力フロー)を持っていることを確認してください。ただし、頻繁に更新されない永続的な記録の場合は除きます。データを受信するだけで、決して出力しないデータストアは「シンク」エラーの可能性があり、逆にデータを出力するだけで受信しない場合は「ソース」エラーの可能性があります。
ステップ5:バランスの確認。 レベル1の図を見ている場合、親となるレベル0の図と照合して確認してください。入力と出力が一致していますか? 親プロセスが「注文を受信する」と述べている場合、子プロセスも「注文」データを受信しなければなりません。子プロセスが代わりに「支払い」を受信している場合、図はバランスが取れていないことになります。
この順序に従うことで、マクロ視点からミクロ視点へと移行し、システムアーキテクチャについて包括的な理解を確保できます。
経験豊富なエンジニアですら、DFDを作成する際に誤りを犯すことがあります。読者としてこれらの異常を発見できれば、開発中に大幅な時間を節約できます。これらのエラーを認識することで、システムアーキテクトに適切な質問を投げかけることができます。
ブラックホールとは、プロセスに入力はあるが出力がない状態を指します。データはプロセスに入り、その後消えてしまいます。実際のシステムでは、データが失われていることを意味します。たとえば、「ユーザーを処理する」プロセスが「ログインフォーム」を受け取るが、データベースや確認画面への出力が一切ない場合、データはどこにも行けません。これは、必要な要件が欠けているか、論理のパスが途切れていることを示しています。
ミラクルはブラックホールの反対です。入力を受け取らずに、出力を生成するプロセスを指します。なぜ「売上データ」を読み取らないまま、「売上報告書」が生成されるのでしょうか? これはデータが空から生成されていることを意味し、決定論的なシステムでは不可能です。欠けている入力は特定され、データストアまたは外部エンティティに接続する必要があります。
このエラーは、入力と出力が論理的に一致していない場合に発生します。両方が存在していてもです。たとえば、「税金を計算する」というプロセスの入力が「ユーザー住所」で出力が「合計金額」の場合、変換は不完全です。税率が欠けています。これは、データストアが欠けているか、フローが接続されていないことを示すことが多いです。
きれいなDFDでは、接続がない限り、矢印が互いに交差してはいけません。2つのデータフローが交差すると、それらが相互作用しているのか、単に通り過ぎただけなのかが不明瞭になります。複雑な図では多少の交差は避けられないものの、それはレイアウトが悪い証拠です。良好に設計された図では、フローが明確にルーティングされ、混乱を避けるべきです。
すべての矢印にはラベルが必要です。名前が付いていない矢印は、特定のデータ内容が不明であることを意味します。データストアからプロセスへの矢印が見える場合、どのデータが取得されているかを把握しなければなりません。「データ」というラベルはあまりにも漠然としています。代わりに「顧客リスト」や「有効なセッショントークン」など具体的なラベルを付けるべきです。曖昧なラベルは実装エラーの主要な原因です。
新規エンジニアが最も混乱しやすい点の一つは、データフローダイアグラム(DFD)とフローチャートの違いです。両者とも形状と矢印を使用しますが、意味は根本的に異なります。
注目点: フローチャートは「コントロールフロー」に注目します。操作の順序、決定ポイント(if/else)、ループを示します。次に何が起こるかを答えます。一方、DFDは「データフロー」に注目します。情報の移動を示します。データはどこへ行くのかを答えます。
論理 vs. データ: フローチャートでは、決定用のダイアモンドを見ることができます。標準的なDFDでは見られません。DFDはプロセスが実行されると仮定しており、そのプロセスの分岐論理をモデル化しません。
時間: フローチャートはしばしば時間的な順序を示唆します。DFDは一般的に時間的制約がありません。DFDは、データ依存関係によって示唆されない限り、どのプロセスが先に起こるかを示しません。
ストレージ:フローチャートは通常、データストレージを明示的に示しません。DFDはデータストアをコアコンポーネントとして明示的にモデル化します。
この違いを理解することで、存在しない制御論理を探そうとするのを防ぎます。もし「もし○○なら、それならば△△」のような論理を探しているなら、フローチャートや疑似コードを確認してください。データベースがいつ更新されるかを探しているなら、DFDを確認してください。
DFDを読むことは単なる学術的な演習ではなく、ソフトウェアエンジニアにとって日々の必須事項です。このスキルが現実のシナリオにどう応用されるかを以下に示します。
1. オンボーディングとコードレビュー:新しいチームに参加する際、アーキテクチャドキュメントにはしばしばDFDが含まれます。それらを読むことで、コードに触れる前からデータ依存関係を理解できます。コードレビューの際には、実装が図と一致しているか確認できます。図ではデータがキャッシュへ送信されているのに、コードではデータベースへの書き込みのみが行われている場合、不整合が発見されたことになります。
2. デバッグとトラブルシューティング:機能に問題が発生した際、DFDはデータの経路を追跡するのに役立ちます。ユーザーがプロフィールが更新されていないと報告した場合、DFD上の「プロフィール更新」フローをたどることができます。どのプロセスが関与しているか、どのデータストアがアクセスされているかを確認できます。これはコードを盲目的に検索するよりも、検索範囲を大幅に絞り込むことができます。
3. 要件定義:プロダクトマネージャーと協業する際、要件を可視化する必要があることがよくあります。DFDを理解していれば、要件の洗練に貢献できます。開発開始前に、欠落しているデータフローまたは不可能な変換を発見できます。この前向きなアプローチにより、技術的負債を削減できます。
4. システム統合:マイクロサービスアーキテクチャでは、DFDはAPI契約を定義するために不可欠です。サービス間のデータフローをマッピングすることで、サービスAの出力がサービスBの入力と互換性があることを確認できます。これにより、データ形式の不一致による統合失敗を防ぐことができます。
読んでいる図が長期間にわたり有用であることを保証するため、以下の実践を検討してください。古くなった図は、まったく図がないよりも悪いものです。
高レベルを保つ:DFDにすべての変数名を詰め込まないでください。論理的なデータエンティティに集中してください。「ユーザー入力」は「名前フィールド値」よりも良いです。
一貫した命名を用いる:1つの図における「Customer」が、すべての関連する図でも「Customer」と呼ばれていることを確認してください。異なるエンティティを指さない限り、「Client」や「User」といった同義語は避けてください。
変更時に更新する:コードに大幅な変更が加わった場合、DFDも更新すべきです。バージョン管理された図は、システムの進化の履歴として機能します。
複雑さを制限する:1つの図が込みすぎた場合は、低レベルの図に分解する時期です。良い目安は、レベル0の図に主要プロセスが7~10個以内であることです。
データフローダイアグラムの解釈を習得するには、忍耐と練習が必要です。記号の背後にある論理的な関係を理解することが求められます。データの流れに注目し、異常を特定し、階層構造を理解することで、システム分析に強力なツールを手に入れることができます。
エンジニアリングキャリアを進めるにつれ、さまざまなモデリング手法に出会うことになります。DFDは依然として基盤的なスキルです。入力、変換、出力という観点からシステムを考える力を教えます。このマインドセットは、データベース設計、APIアーキテクチャ、クラウドインフラ構成計画に応用可能です。オープンソースプロジェクトや社内ドキュメントでこれらの図を読み続けることで、データの流れを追うほど、システムアーキテクチャが直感的になっていきます。