複雑なソフトウェアシステムを設計するには、データの流れ方と保存場所を明確に把握する必要がある。構造的なアプローチがなければ、アーキテクチャは脆くなり、保守が難しくなり、論理的な誤りを引き起こしやすくなる。システム工学における最も基盤的なモデリング手法の2つは、データフローダイアグラム(DFD)とエンティティ関係図(ERD)である。両者とも可視化という重要な機能を果たすが、システムの根本的に異なる側面に焦点を当てる。
これらの2つのモデルの違いを理解することは、単なる学術的な演習ではなく、システムアーキテクト、ビジネスアナリスト、開発者にとって実用的な必要不可欠なものである。開発の適切でない段階に適切でないモデルを使用すると、誤解が生じたり、データベースの非効率が生じたり、ビジネスロジックが破綻する可能性がある。このガイドでは、それぞれの図の微細な特徴、具体的な構成要素、および一方が他方を上回る戦略的状況について探求する。
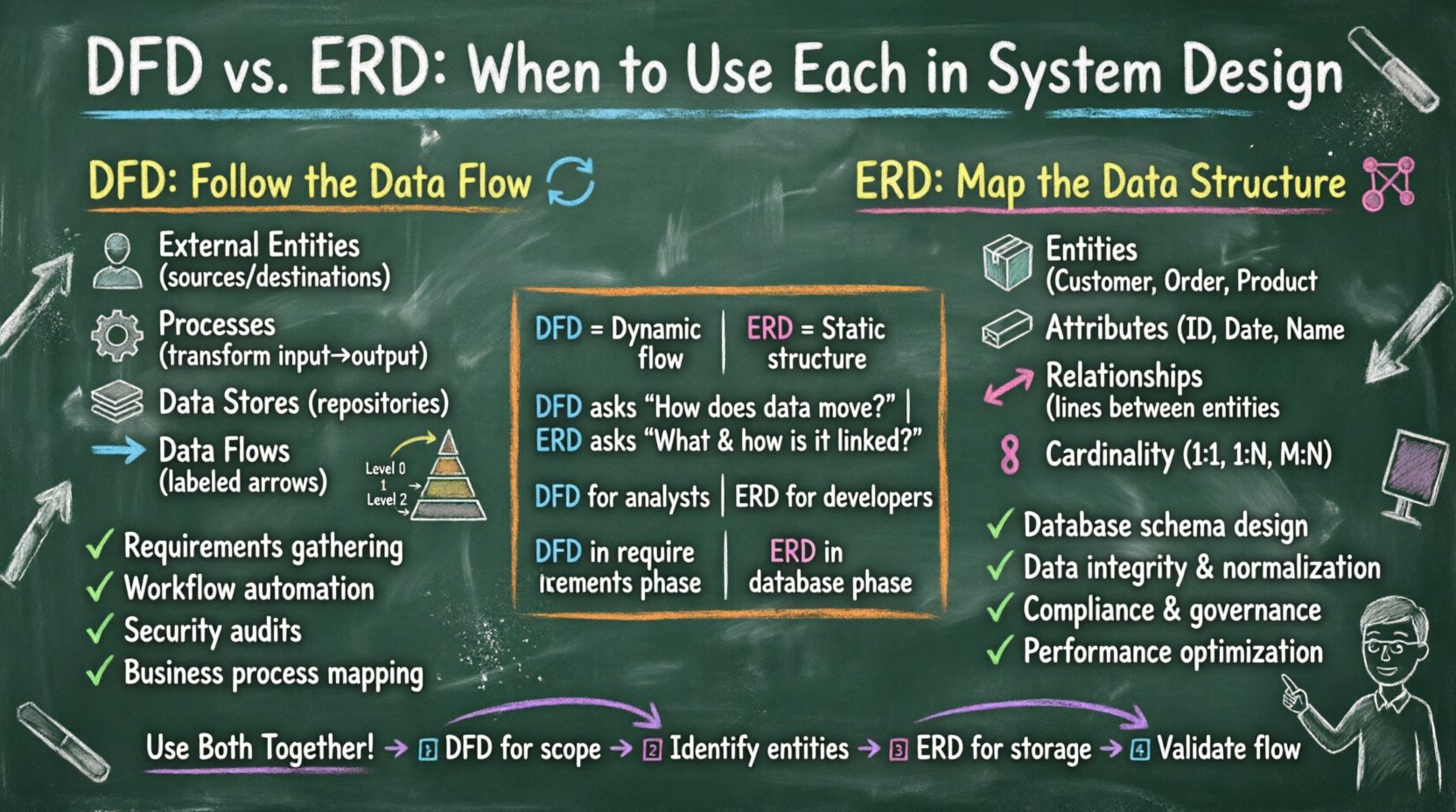
データフローダイアグラム(DFD)の理解 🔄
データフローダイアグラムは、システム内を通過するデータの動きに注目する。情報がどのように処理され、変換され、保存されるかを可視化する。DFDは物理的な実装の詳細やプロセスのタイミングには関与しない。代わりに、情報の論理的な流れを高レベルで提示する。
DFDの核心的な構成要素
- 外部エンティティ: これらはシステム境界外のデータの発信元または受信先を表す。ユーザー、他のシステム、または組織である可能性がある。データの発信または受信は行うが、この特定のモデルの文脈では処理は行わない。
- プロセス: ラウンドされた長方形で表される。入力データを出力データに変換する活動を指す。プロセスは、通過する情報の状態や形式を変える。すべてのプロセスに少なくとも1つの入力と1つの出力があることが不可欠である。
- データストア: これらは後で使用するためにデータを保持するリポジトリである。DFDでは、ファイル、データベース、アーカイブを表す。特定の技術を意味するものではなく、永続的なストレージの存在を示す。
- データフロー: 矢印で表され、データの移動方向を示す。各フローは、転送中のデータパケットの名前でラベル付けされるべきである。データフローはエンティティ、プロセス、ストアを結びつける。
抽象度のレベル
DFDは、複雑さを管理するために通常階層的に作成される:
- コンテキスト図(レベル0): これは最高レベルの視点である。システム全体を単一のプロセスとして表示し、それと相互作用するすべての外部エンティティを特定する。システムの境界を明確に定義する。
- レベル1図: これはコンテキスト図の単一プロセスを主要なサブプロセスに分解する。論理的な詳細に巻き込まれることなく、システムが内部でデータをどのように扱うかのより詳細な情報を提供する。
- レベル2以降: これらの図は、レベル1から特定のプロセスをさらに詳細に分解する。特定のデータ変換を厳密に定義する必要がある複雑なモジュールで、このレベルはよく使用される。
DFDを適用するタイミング
DFDは、要件収集および機能設計の段階で最も効果的である。技術的な制約に気を取られることなく、ステークホルダーがシステムの動作を可視化するのを助ける。特に以下の点で有用である:
- 欠落しているデータ要件の特定。
- 非技術的なステークホルダーにビジネスプロセスを伝える。
- プロジェクトの範囲を定義する。
- 機密データがどこから入力され、どこから出力されるかを特定することで、情報セキュリティを分析する。
エンティティ関係図(ERD)の理解 🔗
DFDが動きを追うのに対し、エンティティ関係図は構造に注目する。ERDは、データベース内のデータ要件と関係を定義するために使用される概念モデルである。データの静的性質を記述し、整合性と正規化を確保する。
ERDのコアコンポーネント
- エンティティ:長方形で表されるこれらは、データが格納される対象となる現実世界のオブジェクトまたは概念です。例として「顧客」、「注文」、または「製品」があります。エンティティはデータ構造の基本単位です。
- 属性:これらはエンティティの性質や特徴を表します。通常、エンティティボックス内にリストされるか、それに接続されます。属性は「顧客ID」や「注文日」などの具体的なデータポイントを定義します。一部の属性は主キーとして機能し、レコードを一意に識別します。
- 関係:ダイヤモンドまたは線で表され、エンティティどうしの相互作用を定義します。関係は、あるエンティティのレコードが別のエンティティのレコードと関連していることを示します。
- 基数:これはエンティティ間の数量的関係を定義します。一般的な基数には1対1(1:1)、1対多(1:N)、多対多(M:N)があります。基数を理解することは、データの重複を防ぐために重要です。
正規化とデータ整合性
ERDは正規化の出発点となることがよくあります。正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスです。ERDは物理的なテーブルを作成する前に対応する論理スキーマを可視化するのに役立ちます。これにより、以下のことが保証されます:
- データが不必要に重複しない。
- 参照整合性が維持される(例:注文は顧客が存在しない状態で存在できない)。
- 一意性や必須フィールドなどの制約が明確になる。
ERDを適用するタイミング
ERDはデータベース設計フェーズで不可欠です。ビジネス要件と技術的実装の間のギャップを埋める役割を果たします。以下の状況で特に有効です:
- リレーショナルデータベースのスキーマを設計するとき。
- データ制約や検証ルールを定義するとき。
- アプリケーション全体でデータの一貫性を確保するとき。
- データ取得の効率性およびインデックス戦略を計画するとき。
一目でわかる主な違い 🆚
これらの2つのモデルを並べて比較することで、それぞれの明確な目的が浮き彫りになります。視覚的な複雑さにおいて似ているように見えるかもしれませんが、目的は大きく異なります。
| 機能 |
データフローダイアグラム(DFD) |
エンティティ関係図(ERD) |
| 主な焦点 |
プロセスとデータの移動 |
データ構造と関係 |
| 時間次元 |
動的(時間の経過に伴う流れを示す) |
静的(ある時点での構造を示す) |
| 核心的な質問 |
データはどのように移動するか? |
どのデータが保存され、どのようにリンクされているか? |
| 対象読者 |
ビジネスアナリスト、関係者 |
データベース管理者、バックエンド開発者 |
| ライフサイクルフェーズ |
要件定義、機能設計 |
データベース設計、実装 |
| 論理 vs. ストレージ |
論理に注目する |
ストレージに注目する |
| 複雑さ |
多くのフローがあるため、複雑になることがある |
関係性があるため、複雑になることがある |
データフロー設計を優先すべきタイミング 📉
DFDがシステム設計の主要なツールとなる特定の状況がある。ビジネスロジックがシステムの中で最も複雑な部分である場合、DFDを最初に選ぶことがしばしば正しい道である。
- ワークフロー自動化: システムが複雑な承認チェーン、状態変更、または複数ステップの取引を含む場合、DFDは処理の順序を明確にする。プロセス内のボトルネックを特定するのに役立つ。
- 外部連携: システムが多数の外部APIやレガシーシステムとやり取りする場合、DFDはデータの流入・流出ポイントをマッピングするのに役立つ。システム間のデータ受け渡しにおける損失を防ぐ。
- セキュリティ監査: セキュリティチームは、機密データがアプリケーション内でどのように流れているかを追跡するためにDFDを頻繁に使用する。暗号化が必要なポイントやアクセス制御を強制すべきポイントを特定できる。
- ビジネスプロセス再設計: 既存のワークフローを最適化する際、DFDは基準となるフレームワークを提供する。『現状』プロセスと『将来』プロセスを比較することで、改善度を測定できる。
このような状況では、ERDに早々に注目しすぎると、システムの論理が曖昧になる可能性がある。データベースが完璧に設計されていても、プロセスフローに問題があれば、アプリケーションはユーザーのニーズを満たすことができない。
データ構造設計を優先すべきタイミング 🏗️
逆に、データの整合性と構造が成功の鍵となる状況もある。データ量、関係性、制約が主導する場合、ERDが優先されるべきである。
- データ集約型アプリケーション: アナリティクスプラットフォームやデータウェアハウスのようなシステムでは、データの構造が極めて重要です。ERDは、スキーマが複雑なクエリや集計をサポートすることを保証します。
- レガシーマイグレーション: 古いシステムから新しいシステムへデータを移行する際、既存の関係を理解することが鍵となります。ERDは古いテーブルを新しい構造にマッピングするのを助け、データの損失や破損が起きないことを保証します。
- コンプライアンスとガバナンス: 金融や医療のような業界では、厳格なデータガバナンスが求められます。ERDはデータがどこに存在するか、誰が所有しているか、他のデータポイントとどのように関係しているかを記録し、コンプライアンス報告を支援します。
- ハイパフォーマンス要件: システムが高速な読み書き操作を要する場合、ERDはインデックス戦略やパーティショニングをガイドします。関係性を理解することで、結合操作を効率的に設計できます。
これらの状況でERDを省略すると、「スパゲッティデータベース」と呼ばれる状態になり、テーブルが重複し、関係性が不明瞭になり、時間とともにパフォーマンスが低下する可能性があります。
両方を統合して堅牢なアーキテクチャを構築する 🤝
DFDとERDの違いを明確にすることは有用ですが、最も成功したシステムは両方を活用することが多いです。これらは互いに排他的ではなく、補完的な関係にあります。堅牢なシステム設計プロセスは、通常、フローから構造へと進んでいきます。
シーケンシャルアプローチ
- DFDで範囲を定義する: フレームワーク図から始め、境界を理解する。すべての入力と出力を特定する。
- プロセスを分解する: プロセスを分解して、必要な特定のデータ変換を理解する。
- データエンティティを特定する: データフローを分析する中で、移動されている永続的なオブジェクトを特定する。これらがERDの候補エンティティとなる。
- ERDを設計する: これらのエンティティがどのように格納され、リンクされるかを定義するため、エンティティ関係図を作成する。
- フローを検証する: データフローをデータベーステーブルに戻してマッピングする。DFD内のすべてのプロセスが、ERDに対応するストレージ操作を持っていることを確認する。
データストアのマッピング
DFDでは、データストアは一般的なプレースホルダーです。ERDでは、同じデータストアが詳細なテーブル定義になります。マッピングプロセスには以下の内容が含まれます:
- DFDのデータストアをERDのエンティティに変換する。
- DFDのフロー内のすべての属性が、ERDの属性に反映されていることを確認する。
- ERDの基数が、DFDのフローの多重性をサポートしているかを確認する。
たとえば、DFDで「顧客」が複数の「注文」を送信している場合、ERDでは顧客エンティティと注文エンティティの間に1対多の関係が反映されるべきです。DFDが複雑な多対多の関係(例:「学生」と「授業」)を示している場合、ERDはそれを解決するために関連エンティティを導入する必要があります。
避けるべき一般的な落とし穴 ⚠️
これらのモデルを混同したり、誤って使用したりすると、大きな技術的負債につながります。以下は注意すべき一般的な誤りです。
1. ロジックとストレージの混同
ERD内に処理論理を含めないでください。ERDは構造を定義すべきであり、動作を定義すべきではありません。ERD内で「処理」を表す矢印を描いていると感じたら、実際にはDFDを記述している可能性が高いです。
2. DFDの過剰モデル化
DFDはコードのフローチャートであってはなりません。すべての条件分岐やエラー処理ルーチンを詳細に記述すべきではありません。DFDは論理レベルで保つべきです。すべての「if-else」文を詳細に記述すると、図が読みにくくなり、高レベルの概要価値を失います。
3. ERDにおける基数の無視
エンティティ間の線を引く際に基数を定義しないのはよくある間違いです。線だけでは、1人の顧客が注文ゼロ件か100万件かがわかりません。曖昧さを避けるために、常に1:1、1:N、またはM:Nを明記してください。
4. データ属性の無視
データ属性が曖昧な場合、両方の図が損なわれます。DFDでは、フローは明確に名前を付けるべきです(たとえば「検証済みの支払い情報」など、「データ」という名前ではなく)。ERDでは、可能な限りデータ型や制約を属性で定義すべきです。
5. 孤立したプロセスの作成
DFDにおいて、データが流入または流出しないプロセスは存在できません。すべてのプロセスボックスが少なくとも1つの流入と1つの流出を持つことを確認してください。孤立したプロセスは、無効な論理や欠落したデータ要件を示しています。
ドキュメント作成のベストプラクティス 📝
明確さと有用性を維持するために、これらのドキュメント作成基準に従ってください。
- 一貫した命名規則:両方の図で同じ用語を使用してください。DFDで「Client」と呼ぶなら、ERDでも「Client」と呼ぶべきであり、「User」とは呼んではいけません。一貫性があることで、チームの認知負荷が軽減されます。
- バージョン管理:図をコードのように扱ってください。バージョン履歴を維持してください。システムが進化するにつれて、図は現在の状態を反映するように更新されなければなりません。
- 文脈的な注記:複雑な領域に注記を追加してください。関係が標準的でない場合は、その理由を説明してください。データフローがバックグラウンドジョブを表す場合は、非同期であることを明記してください。
- レビューのサイクル:ビジネス関係者(DFD用)と技術リーダー(ERD用)の両方と正式なレビューを行ってください。ビジネスアナリストが開発者が見逃す可能性のあるDFDの論理的な欠陥を発見するかもしれませんし、逆もまた然りです。
モデル選択に関する最終的な考察 🧠
データフローダイアグラムとエンティティ関係図のどちらを選ぶかは、片方を他方より選ぶことではありません。それは、設計ライフサイクルの特定の段階に適したツールを選ぶことなのです。DFDはデータが通る経路を明確にし、システムが意図した通りに動作することを保証します。ERDはそのデータを固定し、信頼性と効率性をもって保存されることを保証します。
これらの2つのモデルの異なる目的を習得することで、アーキテクトは論理的に整合性があり、構造的に堅牢なシステムを構築できます。目標は完璧な図を描くことではなく、システムに対する明確な理解を生み出すことです。チームがDFDを見てプロセスを読み取り、ERDを見てデータを読み取れるようになったとき、成功するプロジェクトの基盤が築かれます。
これらのモデルはコミュニケーションツールであることを思い出してください。その価値は、チームメンバー間で共有される理解にあります。複雑な取引をマッピングしている場合でも、ユーザーのプロファイルを定義している場合でも、明確さ、正確性、ビジネス目標との整合性に注目してください。適切なフローと構造の組み合わせがあれば、システム設計は当てずっぽうではなく、 disciplined な芸術形式になります。
 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online