 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











データフローダイアグラム(DFD)は、情報システムの視覚的設計図として機能します。コードが構文を通じて論理を記述するのに対し、DFDは動きを通じて論理を記述します。データがシステムに入り、さまざまなプロセスを経て変換され、出力または保存として出る様子をマッピングします。このガイドでは、独自のツールに依存せずにこれらの図を構築する方法を包括的に解説し、システム分析の基本原則に焦点を当てます。
新しいアプリケーションの要件を定義している場合でも、既存のレガシーシステムを監査している場合でも、データフローを理解することは不可欠です。適切に構成されたDFDは曖昧さを排除します。ステークホルダーが情報の発生源と終了点について合意を促します。この文書では、DFDの構造、その構築を規定するルール、複雑なシステムを管理可能なビューに分解するための手法について探求します。
データフローダイアグラムは制御フローダイアグラムではありません。イベントのタイミングや順序を示すものではありません。代わりに、データそのものに注目します。まるで河川システムの地図と考えてください。水の速さや天候には関心がありません。重要なのは支流、貯水池、そして川の河口です。
ビジネスシステムをモデル化する際、DFDは3つの主要な問いに答えます:
これらの問いに答えることで、ビジネスの論理的表現を作成できます。この表現は、システムを構築するために使用する技術スタックに関係なく、有効なままです。ビジネスニーズと技術的実装の間のギャップを埋める抽象化の言語なのです。
すべてのデータフローダイアグラムは、4つの特定の記号を使って構築されます。メソドロジーによって記法はわずかに異なりますが、根本的な概念は一貫しています。これらの要素を習得することが、正確なモデル化の基盤です。
外部エンティティは、モデル化対象のシステムの境界外にあるデータの発生源または到着先を表します。通常は、主システムとやり取りする人、部門、または他のシステムです。
図では、これらは通常、四角形または長方形で表現されます。常にプロセスに接続されている必要があります。データはどこからともなく突然現れたり、空気中に消えたりしてはいけません。
プロセスは入力データを出力データに変換します。システムのエンジンです。DFDでは、プロセスは通常、円または角丸長方形で示されます。プロセス名は常に動詞+名詞の表現で、行動を示すようにしなければなりません。
各プロセスには、少なくとも1つの入力と1つの出力が必要です。入力はあるが出力がない場合、それは「ブラックホール」と呼ばれます。出力はあるが入力がない場合、それは「ミラクル」と呼ばれます。両方ともモデル化の誤りを示しています。
データストアは、後で取り出すために情報を保存する場所を表します。データベース、ファイルシステム、物理的な書類棚、または一時的なバッファが該当します。プロセスとは異なり、データストアはデータを変更しません。データを保持するだけです。
これらは通常、開放された長方形または二つの平行線として描かれます。データフローを通じてプロセスに接続され、読み取りまたは書き込み操作を示しています。
データフローは、コンポーネントをつなぐ矢印です。これらはエンティティ、プロセス、ストア間でのデータの移動を表します。矢印の先端は移動方向を示します。
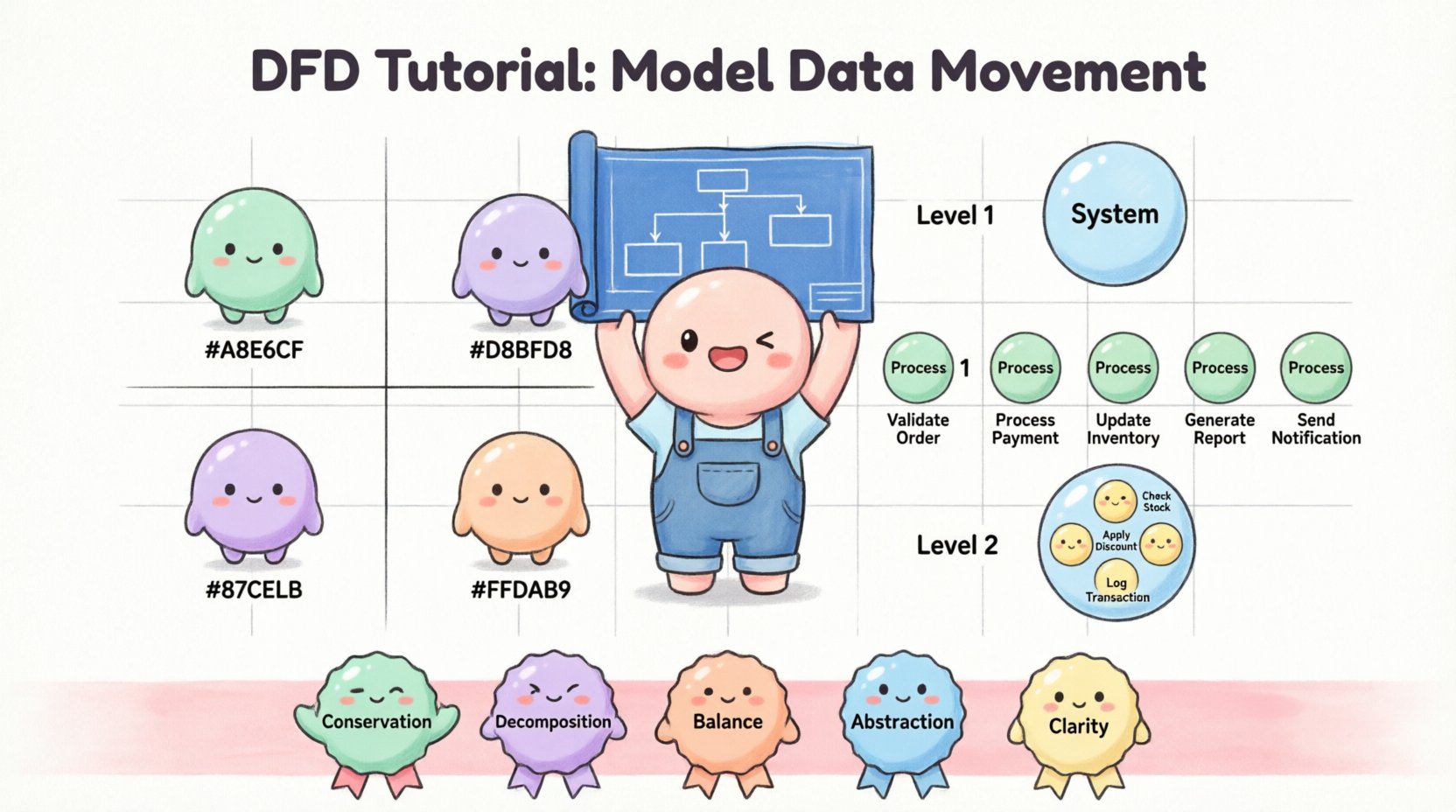
複雑なシステムは1ページに描くことはできません。複雑さを管理するために、DFDは異なる詳細レベルに分解されます。この階層的なアプローチにより、分析者はシステムアーキテクチャを拡大・縮小して確認できます。
コンテキスト図は最も高いレベルの視点です。システム全体を単一のプロセスバブルとして示します。システムが外部エンティティとどのように相互作用するかを説明します。
レベル1では、コンテキスト図の単一プロセスを主要なサブプロセスに拡張します。このレベルでは、システムの主要な機能領域を特定します。
レベル2は、レベル1の特定のプロセスに焦点を当てる。複雑な機能を、より小さな実行可能なステップに分解する。このレベルは、開発者が特定の論理要件を探すことが多い。
システム分析で使用される主な記法は2つある。論理は同じだが、視覚的表現は異なる。適切な記法を選ぶには、チームの慣れ具合と組織の標準に従う必要がある。
| 特徴 | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| プロセスの形状 | 角丸長方形 | 角丸長方形 |
| エンティティの形状 | 正方形 | 正方形 |
| データストアの形状 | 開かれた長方形 | 太い上部・下部を持つ開かれた長方形 |
| データフローの形状 | 曲がった矢印 | 直線矢印 |
| フローのラベル位置 | 線の下 | 線の上または下 |
Gane & SarsonとYourdon & DeMarcoの選択は、主に見た目に関するものである。しかし、一貫性は非常に重要である。1つの文書内で記法を混在させると、混乱を招き、ドキュメントの明確性が低下する。
DFDの構築は体系的なプロセスである。反復と検証が必要である。正確性と完全性を確保するために、以下のステップに従ってください。
1本の線も描く前に、システムの内部と外部にあるものを特定してください。これは通常、プロジェクトの範囲によって決まります。入力を提供するものまたは出力を受けるものは、境界条件です。
すべての情報源と宛先をリストアップしてください。ステークホルダーにインタビューを行い、システムとやり取りする人物を特定してください。自動化されたシステムを忘れないでください。それらも人間と同じようにエンティティです。
全体像から始めましょう。システムを1つのバブルとして描きます。外部エンティティを矢印でつなぎます。矢印には交換されるデータをラベル付けします。これにより、以降のすべての図の基盤ができます。
1つのバブルをレベル1に展開します。主要な機能を特定します。システムを論理的な部分に分割します。レベル0の図の入力と出力が、レベル1のプロセスの集約された入力と出力と一致していることを確認してください。
データを永続化する必要がある場所を特定してください。プロセスが以前の取引からの情報を記憶する必要がある場合、データストアが必要です。これらのストアを関連するプロセスに接続してください。
これは重要なルールです。親プロセスの入力と出力は、その子プロセスの入力と出力の合計と等しくなければなりません。コンテキスト図に「注文受領」と表示されている場合、レベル1の図でもどこかで「注文受領」がシステムに入力されている必要があります。
図を確認してください。データの流れを開始から終了まで追跡します。論理的に流れていますか?孤立したプロセスはありますか?すべてのデータフローにラベルは付いていますか?
経験豊富なアナリストですら、これらのモデルを構築する際に誤りを犯します。一般的な誤りを認識しておくことで、レビュー段階での時間を大幅に節約できます。
システムの論理的視点と物理的視点の違いを明確にすることが重要です。論理的DFDは、システムが何をするかを記述します。物理的DFDは、どうシステムがそれをどう行うか。
論理モデルから始めること。技術的な制約を早々に導入しないこと。技術を早めに導入すると、設計の選択肢が制限され、分析にバイアスが生じる可能性がある。論理モデルが承認されたら、開発をガイドするための物理モデルを導出できる。
DFDがプロジェクトライフサイクル全体を通じて有用なままになるように、これらの基準を遵守する。
これらの図を描くのに時間を投資する理由は何か?文章による要件は誤解されやすい。プロセスを説明する文は複数の読み方をされる可能性がある。図は視覚的で空間的である。
ステークホルダーが図を見ると、すぐに欠落しているフローを発見できる。データが重複している場所も見える。システムの複雑さを一目で理解できる。この視覚的な確認により、間違ったシステムを構築するリスクが低減される。
さらに、DFDはビジネスチームと技術チームの間のコミュニケーションツールとして機能する。ビジネスアナリストは要件を理解するために、開発者はアーキテクチャを理解するためにそれらを使用する。共有されたアーティファクトを維持することで、組織は情報の断片化を減らし、整合性を高める。
データフロー図の手法を実装するには、自制心が必要である。線を引くだけでは不十分。データの保存と分解のルールを理解しなければならない。練習を重ねるうちに、図が思考プロセスの自然な延長となることに気づくだろう。
小さなところから始める。簡単な取引をモデル化する。次に部門に拡大する。最後に、企業全体をモデル化する。レベルを一つずつ上げるごとに、システムに対する理解が深まる。完璧な図を作ることではなく、情報の流れを明確に示す地図を作成し、堅牢なソフトウェアソリューションの構築をガイドすることを目指す。
思い出そう。図はファイル保管用の文書ではなく、思考の道具である。仮定を問い直し、ギャップを特定し、論理を検証するために使うこと。システム設計の世界において、明確さこそが最高の正確さである。
これらの原則に従うことで、あらゆるビジネスシステム内のデータの流れが正確に記録され、プロジェクトライフサイクルに関与するすべてのステークホルダーが理解できることが保証される。