 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











アジャイル開発は、スピード、柔軟性、最小限の文書化としばしば関連付けられる。一方、データフローダイアグラム(DFD)は、歴史的に構造的で計画主導の環境で発展してきた古典的なシステムモデリング手法である。一見すると、これら二つのアプローチは矛盾しているように思える。しかし、適切に実装された場合、DFDはアジャイルフレームワーク内において抽象的な要件と具体的なシステムアーキテクチャの間を結ぶ重要な橋渡しとなる。このガイドでは、データの移動を可視化することで、明確さや制御を失うことなく反復的な開発を支援する方法を検討する。
情報がどこから来ているか、どのように変換され、どこに落ち着くかを理解することは、堅牢なソフトウェアを構築する上で不可欠である。マイクロサービスアーキテクチャを設計している場合でも、モノリシックなアプリケーションをリファクタリングしている場合でも、データフローの原則は常に一定である。実際の応用、統合戦略、そしてDFDがスプリントサイクルに与える具体的な価値について検討する。
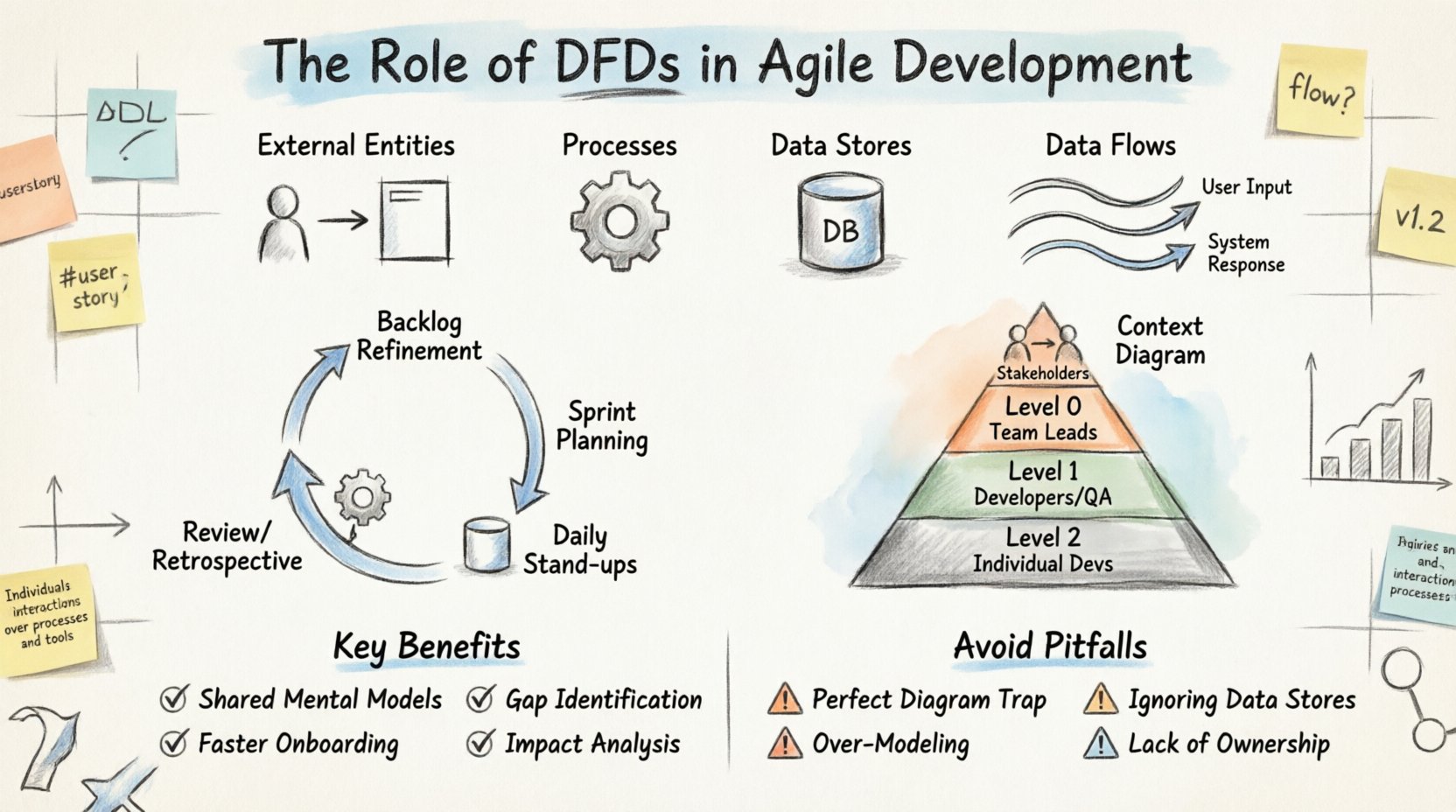
データフローダイアグラムとは、情報システム内を流れているデータの流れを図式化したものである。フローチャートが制御論理や決定ポイントを示すのに対し、DFDはデータに焦点を当てる。外部の情報源から始まり、プロセスを経てデータストアへ、最終的に外部の宛先へとデータが移動する様子をマッピングする。
アジャイル環境では、これらの図は静的な設計図ではない。製品と共に進化する動的なアーティファクトである。DFDの主要な構成要素は以下の通りである:
開発者やプロダクトオーナーがDFDを見ると、システムの「どうするか」ではなく「何をするか」を把握する。この違いは極めて重要である。チームがコードを1行も書く前に、すべての必要なデータが考慮されていることを検証できる。
アジャイルチームの間でよく見られる懸念の一つは、図を描くことの認識上の負担である。アジャイル・マニフェストは包括的な文書化よりも動作するソフトウェアを重視している。しかし、これは文書化が価値がないということではない。文書化は有用で、不要な障壁を生まないということである。
DFDがゲートキーピングの仕組みとして扱われると、ボトルネックになることがある。代わりに、DFDはコミュニケーションツールとして扱うべきである。アジャイルワークフローにDFDを残すための主な根拠は以下の通りである:
目標は、何週間もかけて描く完璧な図を作ることではない。再作業を減らすために十分な明確さを生み出すことである。後で修正される白板上の素早いスケッチは、一度も更新されない洗練された文書よりも、しばしばより価値がある。
システムモデリングをアジャイルスプリントに統合するには、自制心が必要である。図は適切なタイミングで、適切な詳細度で作成されなければならない。以下に、DFDが標準的なアジャイル儀式にどのように組み込まれるかを説明する。
精査の段階では、チームはエピックをストーリーに分解します。このタイミングが高レベルのDFDを策定するのに最適です。これにより、チームはデータ移動に関するエピックの範囲を理解しやすくなります。たとえば、レガシーシステムから新しいダッシュボードへ顧客データを移動するエピックの場合、DFDは必要な変換ステップを明確に示します。
スプリントバックログが確定したら、チームは詳細に掘り下げることができます。複雑なストーリーの場合、レベル1またはレベル2のDFDを作成する場合があります。これにより、ストーリーに割り当てられた開発者がデータ依存関係を理解できるようになります。これにより、開発者が下流プロセスが処理できない形式のデータを想定してエンドポイントを構築してしまうような状況を防ぎます。
毎日図を描く必要があるわけではありませんが、ブロッカーはしばしばデータ整合性に関連します。データストアにインデックスが欠けている、または権限の問題でフローがブロックされている場合、DFDを参照することで、期待される状態と実際の状態の違いを明確にできます。
スプリント終了後、チームはDFDが実装されたコードと一致しているか確認すべきです。アーキテクチャがずれていれば、図を更新する必要があります。この習慣により、将来のスプリントで信頼できる関連性のあるドキュメントを維持できます。
すべての機能が、すべてのデータ取引を深く掘り下げる必要があるわけではありません。開発ライフサイクル内では、DFDの異なるレベルがそれぞれ異なる目的を果たします。適切なレベルを使用することで、不足仕様と過剰設計の両方を防ぐことができます。
| レベル | 焦点 | 使用するタイミング | 主な対象者 |
|---|---|---|---|
| コンテキスト図 | システム境界と外部との相互作用。 | プロジェクト開始時または高レベルの計画段階。 | ステークホルダー、アーキテクト |
| レベル0(高レベル) | システム内の主要なプロセス。 | システム設計フェーズまたは主要機能の計画段階。 | チームリーダー、シニア開発者 |
| レベル1(中レベル) | 主要プロセスの分解。 | 複雑な機能のスプリント計画。 | 開発者、QA |
| レベル2(詳細) | 特定のデータ変換。 | 複雑なロジックまたは統合ポイントのコーディング段階。 | 個別の開発者 |
アジャイルチームでは、コンテキスト図から始め、特定の機能が必要とされる場合にのみレベル1またはレベル2まで掘り下げるのが一般的です。このタイムリーなモデル化アプローチにより、次のイテレーションで変更される可能性のある詳細に無駄な努力を費やすことを防ぎます。
アジャイルにおけるDFDの最も実用的な応用の一つは、それを直接ユーザーストーリーにマッピングすることです。ユーザーストーリーはユーザー視点から機能を記述します(例:「ユーザーとして、プロフィールを更新したい」)。DFDはその機能の裏にあるデータのメカニズムを記述します。
「支払いの処理」というストーリーを考えてみましょう。ユーザーストーリーは成功状態に注目します。一方、DFDはお金のデータの流れに注目します。これらを組み合わせることで、チームは機能要件が技術的な現実によって支えられていることを確認できます。
以下がマッピングの仕組みです:
このマッピングは受入基準の作成に役立ちます。DFDに「取引ログ」ストアへのフローが示されている場合、受入基準にはログエントリが正常に作成されたことを検証する内容が含まれる必要があります。これにより、図とテストケースの間でトレーサビリティのリンクが作成されます。
現代のアプリケーションは、複雑なデータ構造、ネストされたオブジェクト、非同期処理を頻繁に扱います。従来のDFDは、変更を加えずに非同期キューまたはイベント駆動型アーキテクチャを可視化するのに苦労します。アジャイルの文脈では、記法をシステムの現実に合わせて調整することが重要です。
イベント駆動型システムでは、データフローはイベントがプロセスをトリガーするものと見なすことができます。キューを使用する場合、データストアはメッセージブローカーを表します。APIを使用する場合、データフローはリクエスト/レスポンスのサイクルを表します。基本的な原則は同じです:情報を追跡すること。
マイクロサービスを扱う際には、DFDを拡張してサービス間の通信を示すことができます。これは遅延や障害ポイントを理解するために不可欠です。Service AがService Bにデータを送信する場合、DFDによってその依存関係が明確になります。モノリスでは、この依存関係はパフォーマンス上の問題が発生するまで見えないことがあります。
DFDは会話の促進に優れています。言語に依存しないため、ビジネスアナリストと開発者が同じアーティファクトについて混乱なく議論できます。ただし、図がアクセス可能で読みやすいことが前提です。
コラボラティブな図示のためのベストプラクティスには以下が含まれます:
図がリポジトリに保存されると、継続的インテグレーションパイプラインの一部になります。自動チェックにより、特定の文脈において図がデプロイされた構成と一致しているかを検証できますが、これは高度な使い方です。
最高の意図を持っていても、チームはDFDを誤って適用してしまうことがある。これらの落とし穴を早期に認識することで、時間と労力を節約できる。
チームはときどき、図が見栄えよくなるようにしすぎてしまう。アジャイル開発では、完璧な文書よりもざっくりとしたスケッチのほうが良い。見た目ではなく、明確さに注目すべきだ。開発者がスケッチから流れを理解できれば、それ以上は必要ない。
プロセスに注目しすぎて、データがどこに保存されているかを忘れてしまうのは簡単だ。他のプロセスが読み込まないストアに書き込むプロセスは、無駄な負荷である。更新されないストアから読み込むプロセスがある場合、そのデータは古くなっている。データストアを定期的に見直すことで、図の正確性が保たれる。
すべての変数が図に線を引く必要があるわけではない。高価値のデータフローに注目すべきだ。システムの設定がめったに変更されない場合、詳細なフローラインは必要ないかもしれない。過剰なモデル化はノイズを生み出し、図の保守を難しくする。
コードが変更されたときに、DFDの更新を誰が責任を持って行うのか?誰も所有しなければ、すぐに陳腐化してしまう。図の所有権をその特定ドメインのチームリーダーまたはアーキテクトに割り当てるべきだ。
DFDを使用することでアジャイルチームが実際に助けられているかどうかはどうやって知るのか?時間をかけて以下の指標を確認しよう:
これらの指標が改善された場合、モデル化への投資は正当化される。そうでなければ、チームは図の詳細度や更新頻度を再評価すべきだ。
多くの業界では、データの取り扱いが規制されている。金融データ、健康記録、個人情報は、保存や移動に関して厳格な要件がある。DFDは、コンプライアンス監査において特に有用である。
DFDは、機密データがシステムに入力される場所、どのように暗号化されるか、どこに保存されるか、そしてどこから出力されるかを明確に示す。この可視化は以下の点で不可欠である:
機密データを含むアジャイルスプリントでは、コードがマージされる前にセキュリティチームによるDFDのレビューが必要である。これにより、開発ライフサイクルにセキュリティを組み込むことができるが、スピードを落とさずに済む。
多くのアジャイルチームは、レガシーシステムの近代化に取り組んでいる。これは、古い機能を新しいAPIでラップする、またはデータを新しいプラットフォームに移行する作業を含むことが多い。DFDは、この文脈で非常に価値がある。なぜなら、レガシーコードの「ブラックボックス」を文書化できるからである。
レガシーシステムのDFDを作成することで、データ移行のエントリポイントとエグジットポイントを特定できる。これにより、古いシステムと新しいシステムの間の接続設計が容易になる。移行中にデータが失われず、新しいシステムがデータを正しく処理することを保証する。
データフローダイアグラムをアジャイル開発に統合することは、重い文書化に戻ることではありません。システムのアーキテクチャについて明確な理解を保ちながら、反復的な変更を受け入れることです。DFDを静的な要件ではなく、生き生きと進化するツールとして使うことで、コミュニケーションが向上し、リスクが低減され、提供されるソフトウェアの品質が向上します。
この手法を取り入れるチームは、データ管理に関する技術的負債が減少することを発見します。データの問題をデバッグする時間は減り、機能の開発に時間を割けるようになります。重要なのはバランスです。価値をもたらすときに図を作成し、システムが変化したときにそれを更新してください。そして常に最終的な目標を意識してください:正しくかつ効率的に動作するシステムを構築することです。