 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











システム統合は現代のデジタルインフラの基盤です。異なるアプリケーション、データベース、サービスを統合し、一貫した単位として機能させることが目的です。しかし、これらのシステム間を移動するデータの複雑さは、すぐに見えにくくなることがあります。このような状況で、データフローダイアグラム(DFD)の存在が不可欠になります。DFDは、データがシステム内でどのように移動するかを視覚的に表現し、入力、処理、保存、出力の各要素を強調します。システム統合に適用すると、データのルートや依存関係を理解するための設計図として機能します。
明確な地図がなければ、統合プロジェクトはデータの不整合、セキュリティ上の脆弱性、ボトルネックのリスクに直面します。複数のコンポーネントにわたるデータの流れを可視化することで、アーキテクトやエンジニアは、重大な障害になる前にギャップを特定できます。このガイドでは、複雑なシステムを統合する文脈において、DFDをどのように使うかという手法について探求します。
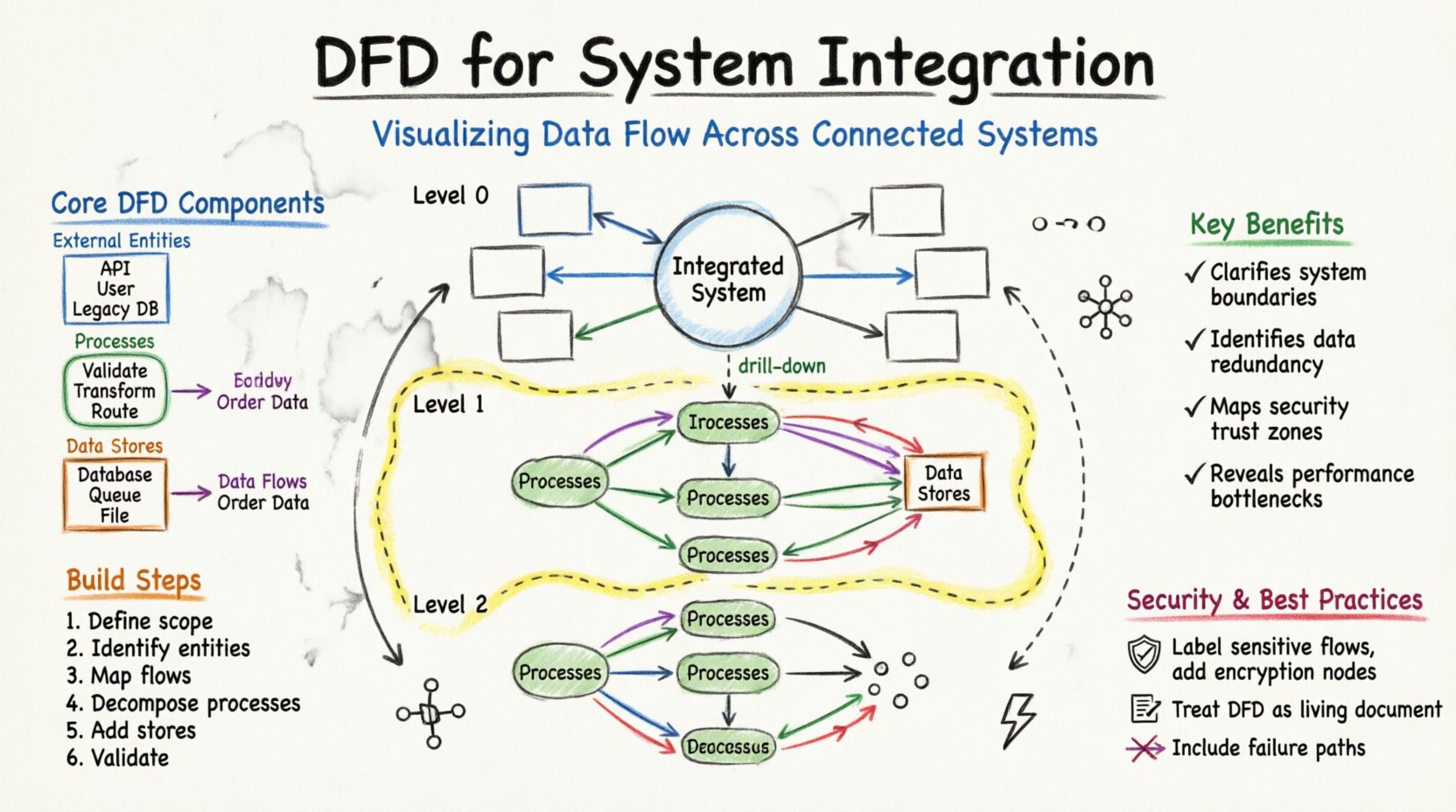
統合の詳細に突入する前に、DFDの基本的な構成要素を理解することが必要です。これらの要素は、システムの複雑さに関わらず一貫して保持されます。
DFDとフローチャートの違いを明確にすることが重要です。フローチャートは制御フローと決定論理(if/elseの経路)に注目します。一方、DFDはデータの移動にのみ焦点を当てます。システム統合においては、特定の決定経路よりもデータの整合性の方が重要であることが多くあります。そのため、データ変換パイプラインをマッピングするにはDFDが最も適したツールです。
複数のシステムが通信を必要とする場合、アーキテクチャはメッシュ構造に似ることがあります。中央の可視化がなければ、接続は絡み合ったネットワークになりがちです。DFDは情報を階層化することで、この複雑さを明確にします。
複雑さを管理するために、DFDは通常、異なる抽象度のレベルで作成されます。この階層構造により、ステークホルダーは高レベルの概要から具体的な技術的詳細まで、システムを段階的に把握できます。
コンテキスト図は、最も高い抽象度のレベルです。統合されたシステム全体を単一のプロセスとして扱います。システムと外部エンティティとの相互作用を示します。
この図は主プロセスを主要なサブプロセスに分割する。統合アーキテクトにとっての主要なマップである。
レベル2の図は、レベル1から特定のサブプロセスに詳細を掘り下げる。開発者やエンジニアが特定のロジックを実装する際に使用される。
信頼性の高いDFDを作成するには構造的なアプローチが必要である。単なる図面描画ではなく、ビジネスロジックを理解する必要があるモデル化作業である。
統合に参加するすべてのシステムをリストアップすることから始める。データを生成するシステムとデータを消費するシステムを区別する。組織の境界を定義する。どのデータフローが内部で行われ、どのデータフローがパブリックドメインに跨るのか?
すべてのソースと宛先をリストアップする。これには以下が含まれる:
エンティティを中央システムに接続する矢印を描く。これらのフローに移動中のデータの種類(例:「注文詳細」、「在庫状況」)をラベル付けする。内部ロジックについてはまだ心配しないでください。移動に注目する。
中央システムを論理的なプロセスに分割する。たとえば、「注文処理」という1つのプロセスではなく、「注文検証」、「在庫確認」、「支払い処理」に分ける。この分解により、データが変換される場所が明らかになる。
データを保存する場所を特定する。統合では、一時的なステージング領域または永続的なウェアハウスである可能性がある。すべてのデータストアが、書き込みを行うプロセスと読み取りを行うプロセスに接続されていることを確認する。
一般的な誤りを確認する。データフローが何もない場所から始まったり、終わったりしないようにする。すべての矢印には開始点と終了点が必要である。データが永続化が必要な場合、データストアが迂回されないことを確認する。
統合用DFDを構築することは、障害がないわけではありません。データの不整合や隠れた依存関係は一般的な落とし穴です。以下の表は、頻発する問題とそれらを解決するための推奨アプローチを概説しています。
| 課題 | 説明 | 解決策 |
|---|---|---|
| データの重複 | 複数のシステムが、顧客情報を独立して保存している。 | 可能な限り、DFD内のデータストアを1つの信頼できるソースに統合する。 |
| 隠れた依存関係 | データフローが、図に表示されていないバックグラウンドタスクに依存している。 | 非同期プロセスやバックグラウンドジョブを、DFD内の明示的なプロセスとして含める。 |
| セキュリティの穴 | 暗号化されていないデータがパブリックネットワークを横断して流れている。 | セキュアなフローにラベルを付け、ネットワーク境界で暗号化プロセスを適用する。 |
| レガシーシステムのインターフェース | 古いシステムには標準APIが存在しない。 | データ形式を変換するために必要なラッパーまたはミドルウェアをモデル化する。 |
| ボリュームの急増 | ピーク時間中にデータフローが予期せず増加する。 | 処理前にトラフィックの急増を吸収するため、バッファリング用のデータストアを追加する。 |
DFDが長期間にわたり有用であることを確保するため、これらの設計原則に従ってください。複雑すぎる図は読みにくくなり、逆に単純すぎる図は正確でなくなることがあります。
システム統合では、データがそのまま移動することはめったにありません。フォーマットが変更され、フィールドが追加され、値が計算されます。DFDはこれらの変換を反映しなければなりません。
データがシステムに入力される際、しばしば標準化が必要です。たとえば、あるシステムでは日付フォーマットが「DD/MM/YYYY」、別のシステムでは「YYYY-MM-DD」であることがあります。DFDには「フォーマット標準化」を目的としたプロセスノードを明示的に示すべきです。
場合によっては、他のデータソースと統合することでデータに価値を加えます。たとえば、注文データに現在の為替レートを組み込むことがあります。これには、二次的なデータソース(たとえば為替レートストア)からデータを取得し、主なデータフローと統合するプロセスが必要です。
セキュリティ要件により、機密データを隠すことが求められることがあります。プロセスがデータをログ記録システムに送信する場合、データがセキュアゾーンを出る前に、クレジットカード番号や社会保障番号をマスクする変換ステップをDFDに示すべきです。
異なるアーキテクチャパターンは、データフローの利用方法が異なります。これらのパターンを理解することで、正しいDFDを描くのに役立ちます。
DFDは一度だけ作成するものではない。システムは進化し、新しいAPIが導入され、古いAPIは非推奨になる。古くなった図はバグやセキュリティ侵害を引き起こす可能性がある。維持管理はDFDライフサイクルの重要な段階である。
DFDの更新は以下の要因によってトリガーされるべきである:
図をコードベースまたは構成ファイルとリンクした状態に保つ。開発者がデータマッピングスクリプトを変更する際には、同時にDFDも更新すべきである。これにより、ドキュメントが真実の情報源のまま保たれる。
セキュリティは追加機能ではなく、データフローの根本的な側面である。データを可視化する際には、信頼境界がどこにあるかを検討しなければならない。
実際の応用を説明するために、企業がウェブサイト、モバイルアプリ、および実店舗を通じて製品を販売する状況を検討する。
エンティティには、ウェブサイト、モバイルアプリ、POSシステム、および顧客が含まれる。
主要なプロセスには「注文受領」、「在庫控除」、「支払い処理」が含まれる。
顧客が商品を購入する際には:
この可視化により、在庫ストアがダウンしている場合、注文受領は成功する可能性があるものの、納品は失敗するという点が明確になります。この依存関係は図のみから確認できます。
データフローダイアグラムは、複雑なシステム統合における情報の流れを理解するための構造化された方法を提供します。抽象的なコードやAPI呼び出しを、ステークホルダーが理解できる視覚言語に変換します。ここに示された手順に従うことで、チームはデータアーキテクチャの正確な地図を作成できます。
効果的なDFDは、より良いシステム設計、統合エラーの減少、明確なセキュリティ境界をもたらします。開発と保守をガイドする動的な文書として機能します。データが最も貴重な資産である環境では、その流れを可視化することは選択肢ではなく、運用の優れた状態を実現するための必須事項です。