 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











データフローダイアグラム(DFD)は、システム分析と設計における基本的なツールです。情報がシステム内でどのように移動するかを視覚的に表現します。DFDの深さを理解することは、要件を正確に捉えるために不可欠です。このガイドでは、高レベルのコンテキスト図から詳細なレベル1図へと移行するプロセスを検討します。特定のソフトウェアツールに依存せずに、分解の原則、データ保存の原則、構造的整合性について検討します。
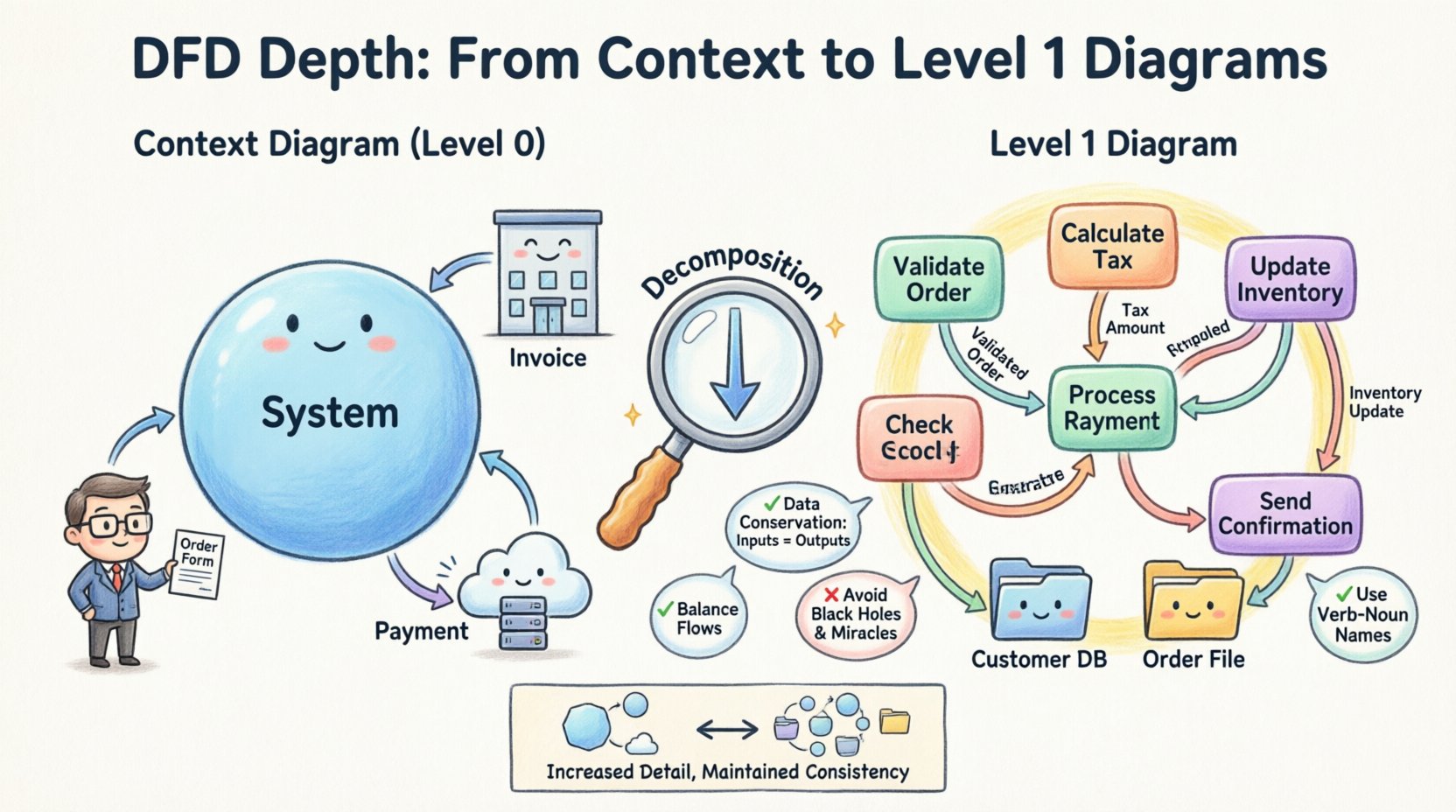
DFDは平坦な文書ではなく、階層構造を持っています。この構造により、アナリストはシステムを異なる詳細度で見ることができます。各レベルで、プロセスとデータフローの詳細が追加されます。
コンテキスト図からレベル1図への移行は、新規のアナリストにとってしばしば最も困難なステップです。明確さと詳細さのバランスを取る必要があります。図が高すぎると、実行可能な情報が不足します。逆に低すぎると、ごちゃごちゃして全体像が見えにくくなります。
コンテキスト図は、すべてのDFDの基盤となります。研究対象のシステムの境界を定義します。円の内側にあるものはすべてシステムの一部であり、外側にあるものは外部です。
境界を明確にすることは非常に重要です。現在のプロジェクトの範囲外にあるエンティティは外部とみなされます。たとえば、給与システムでは税務当局は外部エンティティである可能性がありますが、財務部門は内部である可能性があります。境界の誤認は範囲の拡大と混乱を招きます。
分解とは、複雑なプロセスをより小さく、管理しやすいサブプロセスに分割するプロセスである。これはレベル1図を作成するための核心的なメカニズムである。タスクを分割することだけではなく、システムの内部論理を明らかにすることである。
レベル0からレベル1に移行する際には、論理的一貫性を保つためにいくつかのルールを守らなければならない。
最も重要な技術的要件の一つが、データフローのバランスである。レベル0プロセスに入力されるデータは、レベル1プロセスに入力されるデータと等しくなければならない。同様に、レベル0プロセスから出力されるデータは、レベル1プロセスから出力されるデータと等しくなければならない。
コンテキスト図で「注文フォーム」がシステムに入力されている場合、レベル1図ではその同じ「注文フォーム」がサブプロセスのいずれかに入力されていることを示さなければならない。もしレベル1図で「顧客ID」が内部で渡されている場合、それがレベル0図で外部入力または出力であることはできない。ただし、そのIDがレベル0図にすでに存在していた場合は除く。
分解計画が整うと、実際に構築が開始される。これには、システムの主要な機能領域を特定することが含まれる。
コンテキスト図の単一のプロセスを確認する。問うべきは:システムの目的を達成するために必要な主な活動は何か?これらがレベル1図のバブルまたは円として表れる。
プロセスを矢印でつなぐ。これらの矢印は、内部プロセス間のデータの移動を表す。また、外部エンティティとこれらの新しいサブプロセスをつなぐ矢印も描くことができる。
コンテキスト図ではそれらを除外するが、レベル1図では頻繁にデータストアを含む。データストアとは、データが静止状態で保持される場所である。データベース、ファイル、または物理的なファイルボックスである可能性がある。
データストアを描画する際は:
経験豊富なアナリストですら、DFDを作成する際に誤りに遭遇することがある。これらのパターンを早期に認識することで、検証段階での時間を節約できる。
ブラックホールとは、入力はあるが出力がないプロセスを指す。これは、データが結果を生まないまま消費されていることを意味する。機能的なシステムでは、すべての入力は何かしらの出力またはデータ保存に結びついていなければならない。
ミラクルとは、出力はあるが入力がないプロセスを指す。これは、データが何もないところから生成されていることを意味する。すべての出力は、何らかの入力データから導かれるべきである。
DFDはコントロールフローではなく、データフローを追跡する。コントロールフローとは、プロセスの開始または停止を示す信号(例:「スタートボタンが押された」)を表す。コントロール信号のように見えるフローが見られたら、それは実際にはデータ(例:「スタートリクエスト」)である可能性が高い。DFDはタイミングや論理制御を明示的に扱わない。
レベル1図の入力がコンテキスト図の入力と一致しないときに発生する。レベル1図を描いた後は、常にデータの保存(保存則)を確認する。
以下の表は、どのレベルをいつ使うべきかを理解するのに役立つように、各レベルの違いを要約したものである。
| 特徴 | コンテキスト図(レベル0) | レベル1図 |
|---|---|---|
| 中心プロセス | 1つの単一プロセス | 複数のサブプロセス |
| データストア | なし | はい、含まれる |
| 詳細レベル | 高レベルの概要 | 機能の分解 |
| 外部エンティティ | すべての主要エンティティ | サブセットまたは同じエンティティ |
| 主な目的 | システムの範囲を定義する | 内部論理を定義する |
初期ドラフトの後、図は検証されなければならない。これは一度きりの確認ではなく、見直しと精練のサイクルである。
DFD構造をさらに深く掘り進めるにつれて、粒度に関する意思決定に直面する。どのくらい深くまで掘り下げるべきか?
普遍的なルールはないが、一般的なガイドラインは存在する:
データストアは視覚的な流れを複雑にする可能性がある。論理的に配置されていることを確認する。プロセスを貫く線を引かないでください。線がプロセスを横切らなければならない場合は、通過していることを示すために接続点またはジャンクション記号を使用する。
システム内のアクターと外部のアクターを区別してください。人間のオペレーターがシステムのワークフローの一部である場合(例:データを入力する事務員)、内部のアクターである可能性がありますが、多くの場合、ソフトウェアの境界外にあるため外部エンティティとして表現されます。この定義の整合性が鍵となります。
図は物語の一部にすぎません。論理を説明するために文章による記述が必要です。
コンテキストからレベル1へと成功裏に移行するには、厳密なアプローチが必要です。より多くのボックスを描くことではなく、システムの真実を明らかにすることです。
これらの構造化されたステップに従うことで、システム設計の堅固な基盤が築かれます。レベル1図は開発者のための設計図となり、ビジネス関係者とのコミュニケーションツールにもなります。抽象的な要件と具体的な実装の間のギャップを埋めます。