 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











データフローダイアグラム(DFD)を作成することは、情報がシステム内でどのように移動するかを理解するための重要なステップです。これらの図は、開発者、ステークホルダー、アナリストのための設計図として機能します。しかし、不適切に構築されたモデルは、混乱、開発エラー、システム障害を引き起こす可能性があります。データの流れが誤って表現されると、アプリケーション全体の論理が疑問視されるようになります。このガイドでは、DFDで見られる頻発する誤りを検討し、それらを修正する権威ある戦略を提供します。
多くのチームは、モデリングフェーズを急ぎ、視覚的表現がコードより二次的であると仮定しています。このアプローチは誤りです。DFDは、1行のコードが書かれる前にも論理を定義します。図が不完全であれば、その上に構築されたソフトウェアは、構造的な欠陥を引き継ぐことになります。モデルの整合性を損なう具体的な誤りの種類を検討し、明確な解決策を提示します。
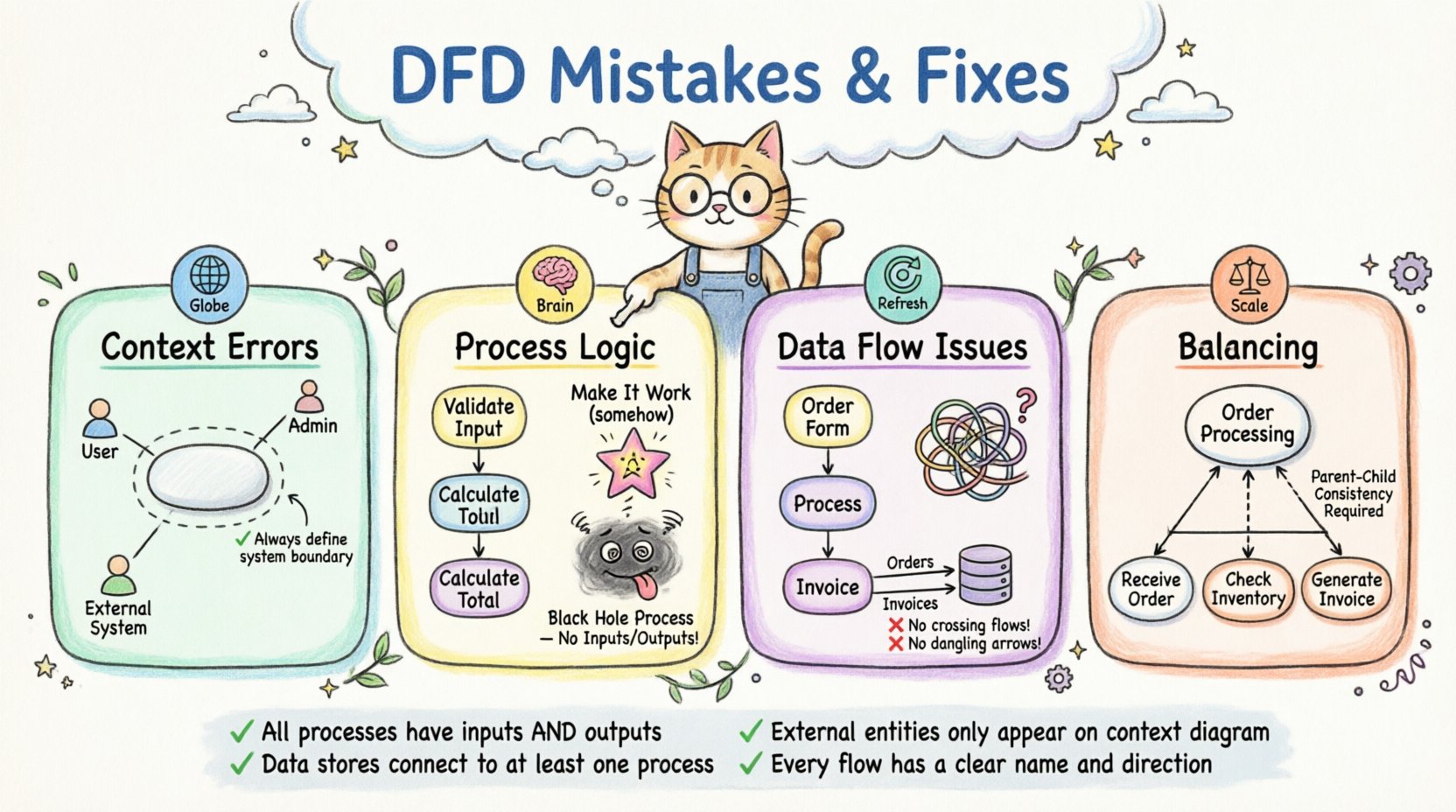
コンテキスト図は、システムの最も高レベルの視点です。システム全体を1つのプロセスとして表し、外部世界との相互作用を示します。ここでの誤りは、その後のすべてのレベルに悪影響を及ぼす基礎を築きます。
外部エンティティは、あなたのシステムとやり取りするユーザー、他のシステム、または組織を表します。よくある誤りは、重要なエンティティを省略することです。ユーザー層や外部APIを忘れる場合、要件は不完全になります。
システムの境界は明確に定義される必要があります。ときには、システム内に属すべきプロセスが外に描かれたり、逆に外にあるプロセスが内に描かれたりすることがあります。これにより、責任の所在が曖昧になります。
プロセスはデータを変換します。これらは図のアクティブな要素です。これらのプロセスの名前付けや定義を誤ると、最も深刻な誤りの一つになります。
プロセス名は動詞+名詞の構造に従うべきです。「Sales」のような名前は名詞です。一方、「Calculate Sales」のような名前は動詞+名詞のフレーズです。この違いは、何のアクションが行われているかを明確にします。
魔法のプロセスとは、入力はあるが出力がない、あるいは出力はあるが入力がないプロセスである。データを何からも作り出したり、結果を返さずにデータを消費したりする。
データがプロセスに入り込むが、出力されるデータがない場合にブラックホールが発生する。情報が虚無へと消え去る。
これはブラックホールの反対である。入力なしにデータがどこからともなく現れる。システムが情報源なしに情報を生成していることを意味する。
DFD内の矢印はデータの移動を表す。これらの矢印の描き方やラベル付けは、システムの振る舞いを理解するために重要である。
データフローの線が交差ノードなしに互いに交差すると、視覚的なごちゃごちゃと混乱を生じる。データが合流するのか、単に通過するのかが不明瞭になる。
データストアは情報が保存される場所を表します。よくある間違いは、プロセスを介さずにデータフローをストアに接続することです。
未接続のフローとは、空中に終わる矢印のことです。これはプロセス、エンティティ、またはストアに接続されていません。
複雑なシステムはしばしば低レベルの図に分解されます。これをレベル化といいます。バランスは、レベル間で入力と出力が一貫していることを保証します。
高レベルのプロセスを低レベルのプロセスに分解する際、子レベルの総入力と出力は親レベルと一致している必要があります。
1つの図に多すぎるプロセスを配置すると、読みにくくなります。理想的には、図は特定の機能またはモジュールに焦点を当てるべきです。
プロセス名はレベル間で一貫していなければなりません。レベル0で「ユーザー検証」と名付けられたプロセスは、レベル1で名前を変更してはいけません。
図を作成することは、戦いの半分にすぎません。検証することで、モデルがビジネスニーズを正確に反映していることを確認できます。
ウォークスルーはステークホルダーと共に図を確認することを意味します。データの入力から出力までの経路を追跡します。その経路は意味があるでしょうか?
図で使用されている用語が、要件文書で使用されている用語と一致していることを確認する。
以下の表は、最も重要な誤りとその修正を要約したものである。
| 誤りの種類 | 説明 | 影響 | 修正 |
|---|---|---|---|
| 魔法のプロセス | 入力も出力もないプロセス | 不可能な論理 | 欠落しているフローを追加する |
| ブラックホール | データは入ってくるが、出ていかない | データ損失 | 出力が存在することを確認する |
| 突然発生 | 入力なしでデータが出現する | 一貫性のないデータ | データの起源を追跡する |
| バランスの取れていないレベル化 | 子の入力が親と異なる | 要件のずれ | フローを調整する |
| 明確でない命名 | 名詞のみのプロセス名 | 曖昧さ | 動詞+名詞を使用する |
| 直接ストア接続 | エンティティはストアに接続する | 論理エラー | プロセスを経由してルートを設定する |
モデルが完成したら、メンテナンスが必要です。システムは進化し、図もそれに合わせて進化しなければなりません。
図の変更を追跡する。重要な変更が加えられた際には、新しいバージョンを保存するべきである。
図を詳細なドキュメントにリンクする。バブルは独自の仕様が必要な複雑なアルゴリズムを表す可能性がある。
DFDの定期的なレビューをスケジュールし、現在のシステム状態と一致していることを確認する。
堅牢なデータフローダイアグラムを構築するには、細部への注意と規律あるアプローチが必要です。上記で述べた一般的な落とし穴を避けることで、システムモデルがコミュニケーションおよび開発の信頼できるツールであることを保証できます。これらの誤りを早期に修正するために費やす努力は、コーディングフェーズで大きな時間を節約します。明確さ、一貫性、論理的な完全性に注目してください。
DFDは動的な文書であることを思い出してください。一度だけ作成するものとして扱ってはいけません。システムが変化するたびに、図は新しい現実を反映するために更新されなければなりません。この継続的な整合性を保つことで、モデルがシステムの有効な表現のまま維持されます。
これらの実践を採用することで、より良いシステムアーキテクチャが実現され、実装段階での驚きが少なくなります。ソフトウェアの品質を支えるために、図の品質を最優先してください。