 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











ソフトウェアプロジェクトは、コードの品質のためではなく、誤解された要件のためでしばしば頓挫する。チームがデータの流れを明確に把握せずに、設計や開発に直ちに着手すると、技術的負債や範囲の拡大が生じる。ここにデータフローダイアグラム(DFD)の価値が現れる。DFDは、ビジネス関係者と技術アーキテクトの間の溝を埋める視覚的言語として機能する。
データフローダイアグラムとは、情報システム内を流れているデータの流れを図式化したものである。フローチャートが制御論理や決定ポイントに注目するのに対し、DFDは情報の流れに注目する。データがシステムに入力される方法、変換される方法、どこに保存されるか、そしてどのように出力されるかを示す。要件収集の文脈において、この違いは極めて重要である。会話の焦点を「システムが何をするか」から「システムが扱うデータは何か.
このガイドでは、DFDのメカニズム、利点、戦略的活用法を検討する。それらが曖昧さを明確にし、検証を支援し、最終製品がビジネスニーズと一致することを保証する方法を検証する。
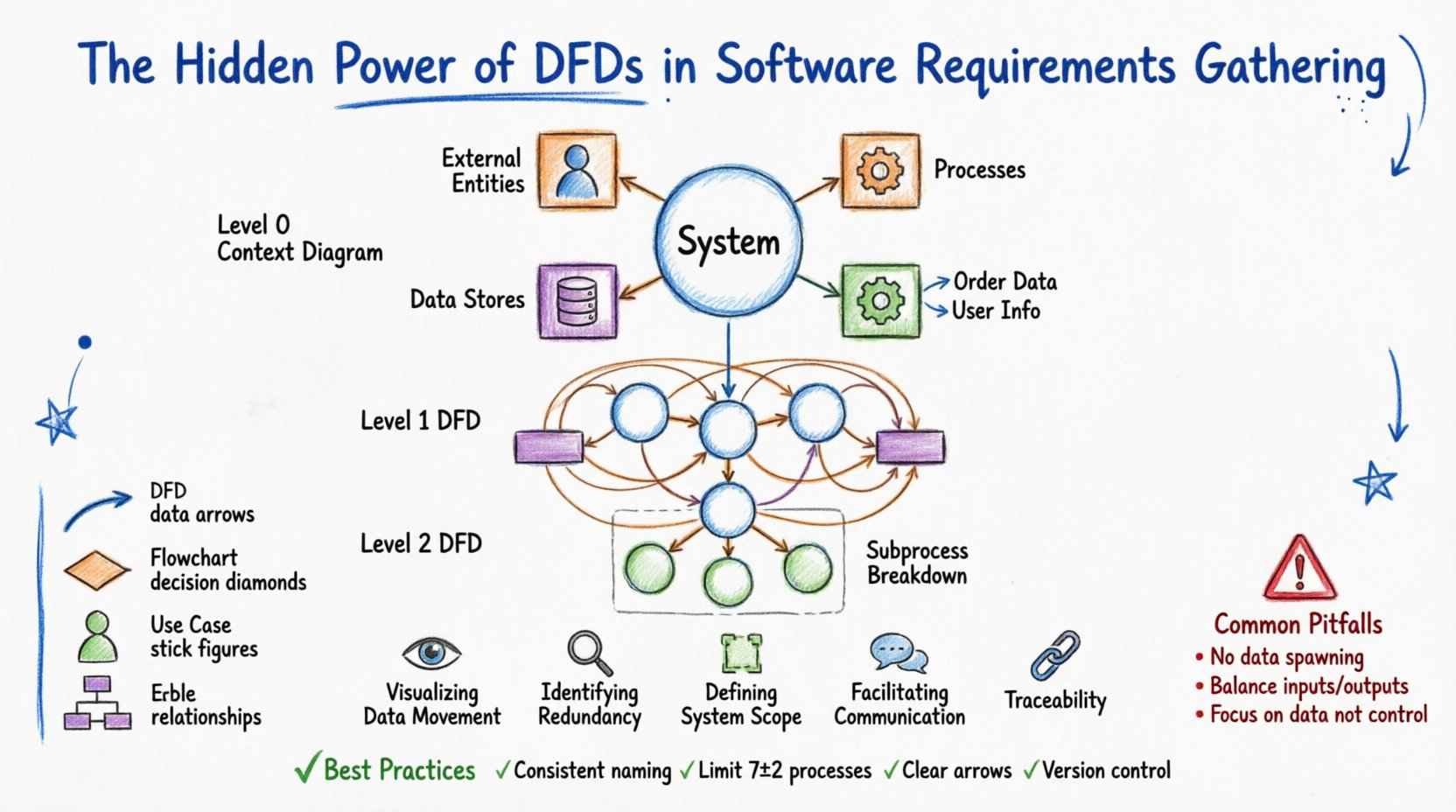
複雑なプロジェクトにDFDを適用する前に、基本構成要素を理解しておく必要がある。DFDは4つの基本要素で構成される。それぞれは特定の幾何学的表現を持ち、システム内での機能について厳密な定義が存在する。
これらの構成要素を理解することで、要件ワークショップ中に混乱を防ぐことができる。関係者はしばしばプロセスとデータストアを混同する。明確な図を用いることで、「顧客」はエンティティであるが、「顧客記録」はストアであることが明確になる。この区別こそ、正確なシステムモデリングの基盤である。
要件文書はしばしば解釈の余地があるテキスト中心の記述に悩まされる。DFDは視覚的で空間的な、唯一の真実の源を提供する。分析段階において、それが不可欠である理由を以下に示す。
DFDは一度に全体像として作成されるものではない。複雑さを管理するために階層的に分解される。このアプローチにより、アナリストは高レベルの概要から始めて、読者を圧倒することなく特定の詳細にまで掘り下げることができる。
これは最高レベルである。システム全体を単一のプロセスとして表す。システムと外部世界との関係を示す。中心に単一のプロセスがあり、データフローで接続されたすべての外部エンティティがその周囲に配置されている。この図は、「システムとは何か、誰とやり取りしているのか?」という問いに答える。
ここでは、コンテキスト図の単一プロセスが主要なサブプロセスに分解される。このレベルには通常5〜9のプロセスが含まれる。システムの主要な機能領域を示す。データストアや外部エンティティを含むが、焦点は主な変換処理にある。
レベル1の各プロセスは、さらにレベル2の図に分解できる。これは複雑な論理に有用である。たとえば、「支払い処理」プロセスは「カード検証」「アカウント請求」「台帳更新」に分解されることがある。プロセスが単一のモジュールまたは関数として実装可能になるほど単純になるまで分解を続ける。
効果的なDFDを作成するには、自制心が必要である。線を引くことだけではなく、論理を正確に捉えることが重要である。品質を確保するために、この構造化されたアプローチに従う。
経験豊富なアナリストですらミスをする。これらの誤りを早期に認識することで、開発フェーズでの時間を大幅に節約できる。以下は、要件モデリング時に最も頻繁に遭遇する問題である。
| 落とし穴 | 説明 | 修正 |
|---|---|---|
| データの突然発生 | 入力元のない状態でデータが突然出現する。 | すべての矢印は、エンティティ、プロセス、またはストアから出発しなければなりません。 |
| データの破棄 | データがプロセスに入りますが、出力や保存なしに消えてしまいます。 | すべての入力が意味のある出力になるか、保存されることを確認してください。 |
| 制御論理 | データフローではなく、DFDを使って決定論理(if/else)を示す。 | 論理制御にはフローチャートを使用し、データ移動にはDFDを使用する。 |
| バランスの取れていない図 | 子図は親図と異なる入力/出力を持つ。 | すべてのデータフローが考慮されていることを確認するために、分解を確認してください。 |
| ゴーストプロセス | データを変更せず、保存もしないプロセス。 | 変換を行わないプロセスは削除してください。 |
| エンティティ間直接フロー | データがシステムを通過せずに、2つの外部エンティティの間を流れます。 | これはシステムの範囲外です。システムはこの相互作用を処理しなければなりません。 |
DFDを他の図示手法と混同することはよくあります。各ツールはソフトウェアエンジニアリングライフサイクルにおいて特定の目的を持っています。どの図をいつ使うかを知ることで、混乱を防げます。
プロジェクトライフサイクル全体を通して図が有用なアーティファクトのまま保たれるようにするため、これらの基準に従ってください。一貫性が、要件モデルの整合性を維持する鍵です。
適切に構築されたDFDの最も強力な特徴の一つは、トレーサビリティマトリクスをサポートできる点である。トレーサビリティにより、すべての要件が満たされ、目的のないものは作成されないことが保証される。
DFDを作成する際、各プロセスおよびデータストアに一意のIDを割り当てることができる。たとえば、プロセスP1.0は要件REQ-001に対応するかもしれない。ステークホルダーが新しい機能を要請した場合、それを特定のプロセスIDにマッピングできる。図内でそのプロセスが見つかれば、データロジックを変更すべき正確な場所がわかる。
これはリグレッションテスト中に特に重要である。もし「利息計算」プロセスが変更された場合、DFDはQAチームに、どのデータフローが影響を受けるかを正確に教えてくれる。彼らは入力(元金)と出力(利息支払い)を特にテストすべきだと理解できる。DFDがなければ、データ変換に関連するエッジケースを見逃す可能性がある。
一部のチームは、DFDがアジャイル手法には重すぎると主張する。彼らはユーザー・ストーリーや受入基準を好む。ユーザー・ストーリーは機能性において優れているが、データフローのシステム的視点を欠くことが多い。DFDは、動的なアーティファクトとして使用すれば、アジャイルに適している。
DFDはしばしばデータ辞書と併用される。データ辞書は、図に表示されたすべてのデータ要素の技術的定義を提供する。データ型、長さ、フォーマットを指定する。
たとえば、図上のデータフローに「生年月日」とラベル付けされたものについて、辞書では「YYYY-MM-DD、ISO 8601、Nullable(null許容)」と定義されるかもしれない。この正確さにより、開発者がデータをどのように保存すべきか推測する余地がなくなる。要件収集段階でDFDとデータ辞書の両方が含まれる場合、データ型の不一致のリスクは著しく低下する。
以下の項目をデータ辞書に含めるよう検討する:
コンセプトからコードへの道のりは、誤解に満ちている。データフローダイアグラムはこの道のりにおいて安定化の役割を果たす。チームがデータ移動の現実に直面するよう強いる。1行のコードも書かれる前に論理的なギャップを明らかにする。
高品質なDFDを作成するための時間の投資は、再作業の削減という利益をもたらす。ステークホルダーが図を検証するとき、それはシステムの論理を検証していることになる。この共有された理解により、ビジネスチームとテクノロジーチームの間の摩擦が軽減される。議論は意見から事実へと移行する。
DFDは静的な成果物ではないことを思い出そう。要件が進化するにつれて、DFDも進化する。コードベースと同様の厳密さで扱うべきである。常に最新の状態に保ち、アクセスしやすくし、開発作業のガイドとして活用する。データモデリングの技術を習得することで、構築するソフトウェアが機能するだけでなく、論理的に整合性があり、ビジネスのニーズに合致していることを保証できる。
DFDの隠れた力は、そのシンプルさにある。実装の詳細のノイズを排除し、核心となる真実に注目する:データは正しく流れなければならない。データが正しく流れれば、システムは機能する。データが欠落しているか、誤って送信されれば、システムは失敗する。このツールを、自信と正確さをもって要件収集を導くために活用しよう。